Release 1.13.162 (Maintenance release) - September 20, 2023
- Bug fixes in the 'Explore-Sequence' feature with respect to job creation and similarity search failures for certain corner cases.
- Bug fix in importing external features through CSV file mapping features to filenames incorrectly when filenames in the CSV are not in sorted order.
- Other UI bug fixes.
Release 1.13.161 (Maintenance release) - September 8, 2023
- Support for text search within the 'sequence explore' job type.
- Fix bug where timestamp was not populated in resultset dump JSON for some video datasets.
Release 1.13.157 (Maintenance release) - September 1, 2023
- Video sequences generated in the 'Explore-Sequence' type of job are generated at a dynamically decided frames-per-second(fps) such that the duration of the video matches the sequence length.
- Enhancement in user experience in presenting video sequences that start close to the end of a video file.
Release 1.13.139 - August 26, 2023
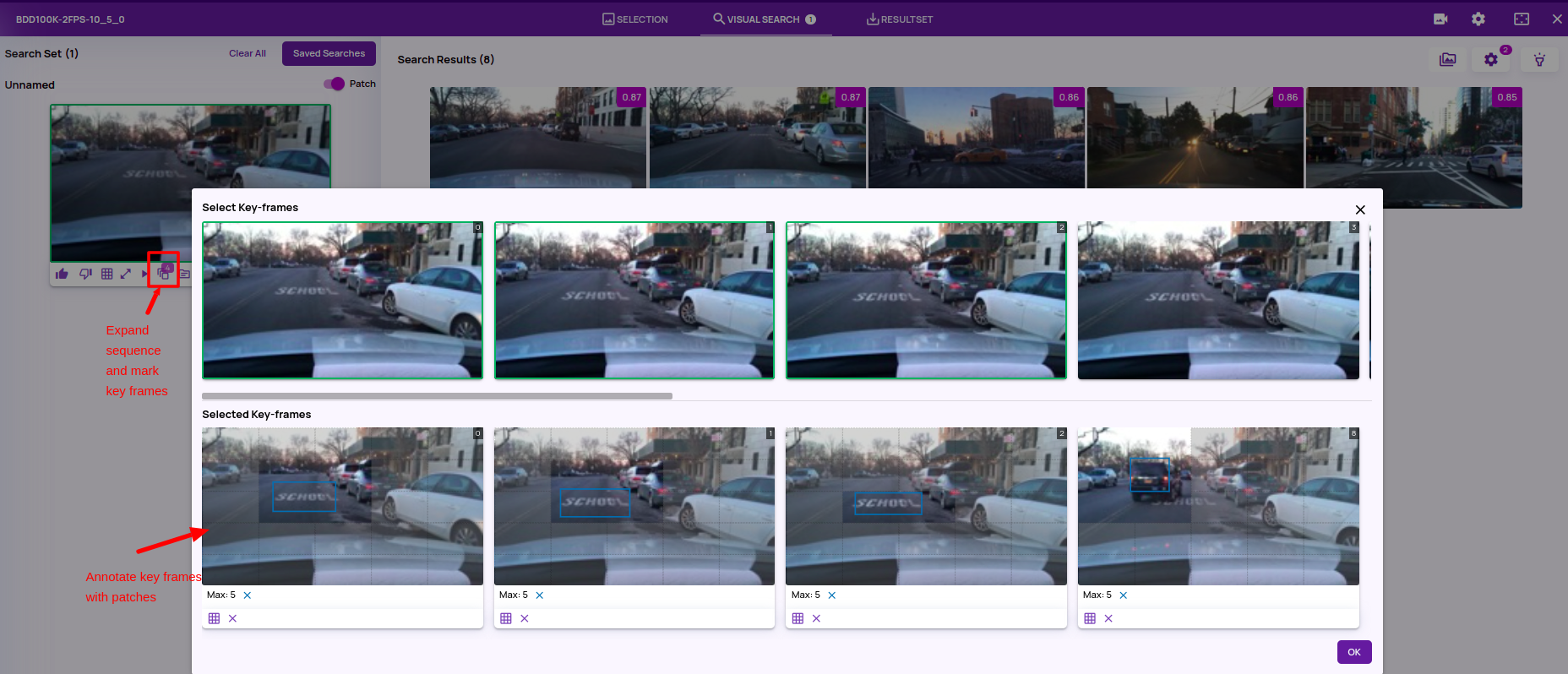
- Video sequence search(BETA): The video sequence search available in the past release allowed querying a video sequence and playing that video sequence. This release supports video sequence search in which a subset of frames in the query sequence can be marked as 'keyframes'. The search finds the matching sequences where the keyframes are present in the same time order that they are present in the query sequence.
.png)
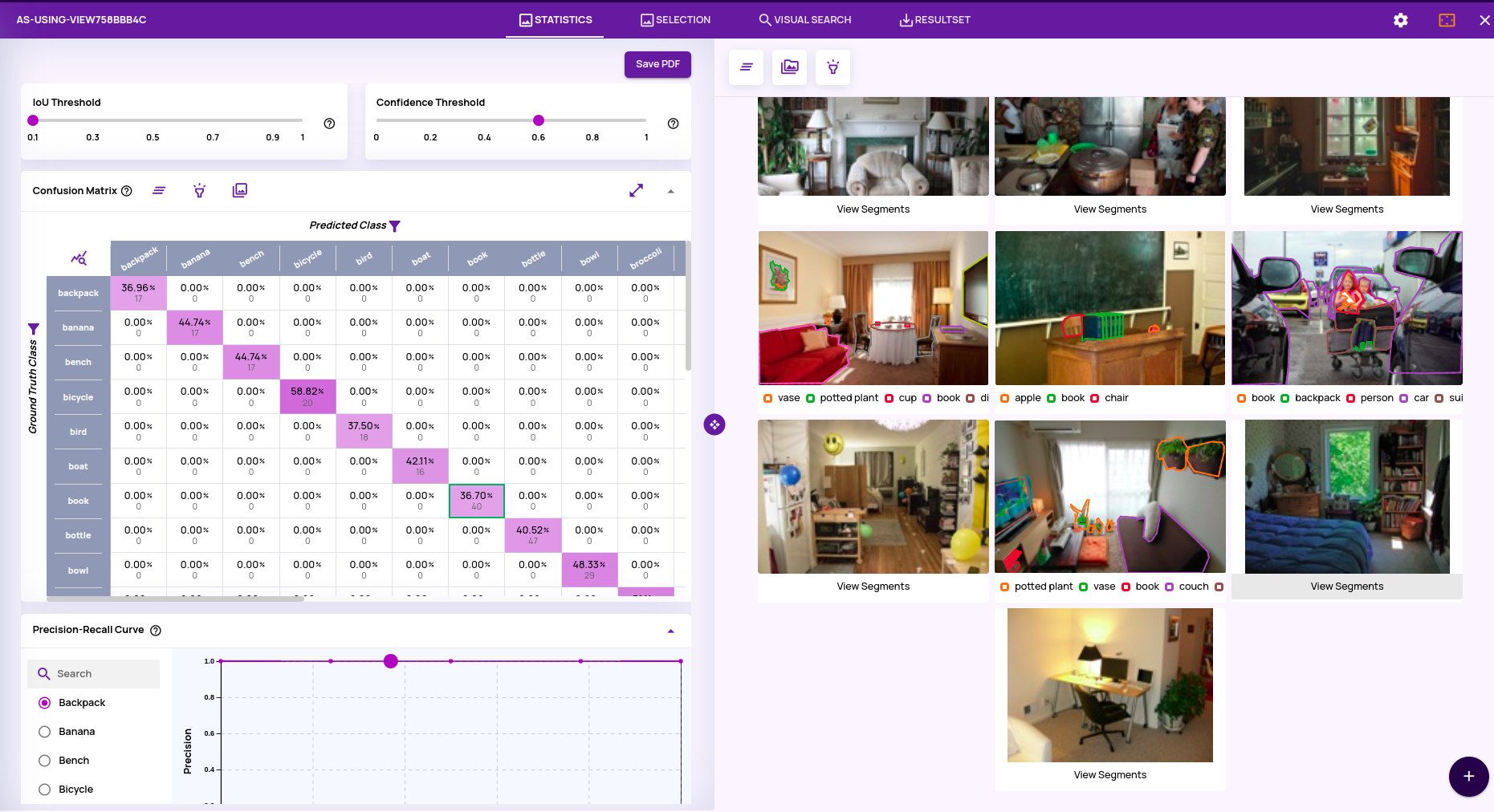
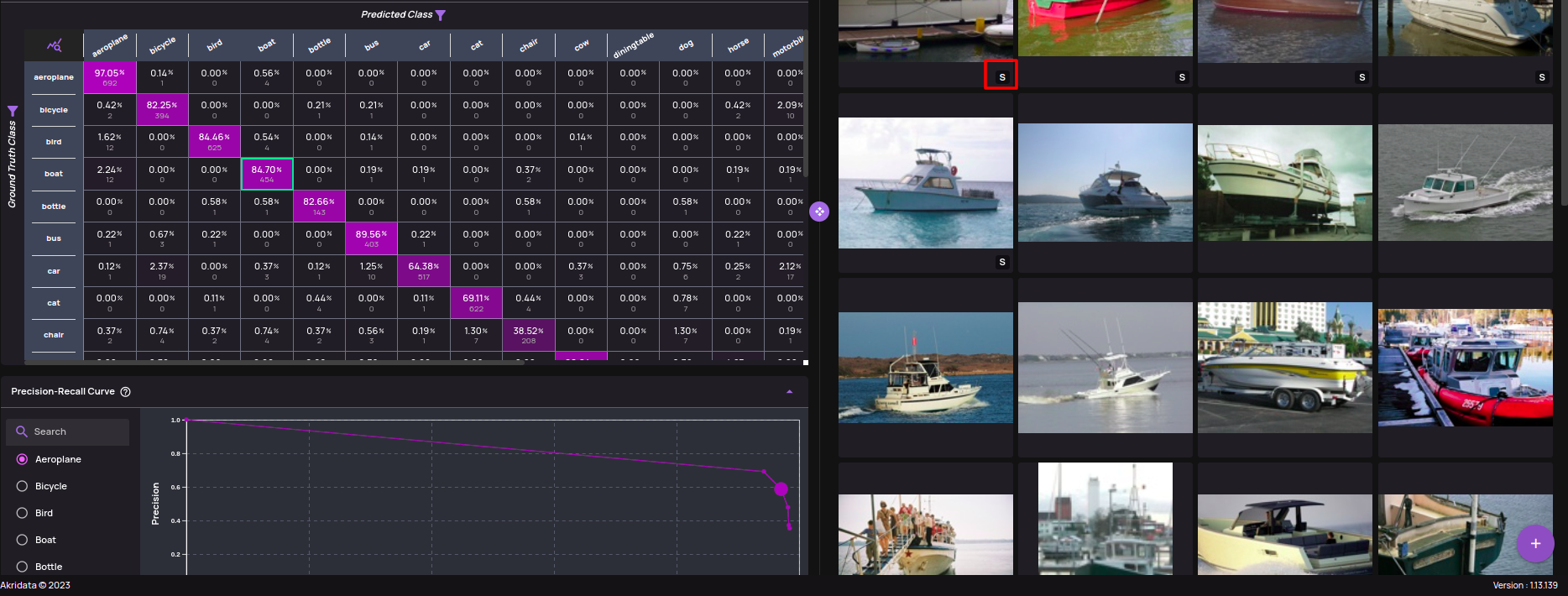
- Model Analysis for Segmentation Models(BETA): An 'Analyze Segmentation' job is added to support model inference analysis on segmentation models. Statistics(Confusion matrix, PR curve, IOU/confidence heatmap) and interactive analysis similar to an 'Analyze object detection' type of job are available.
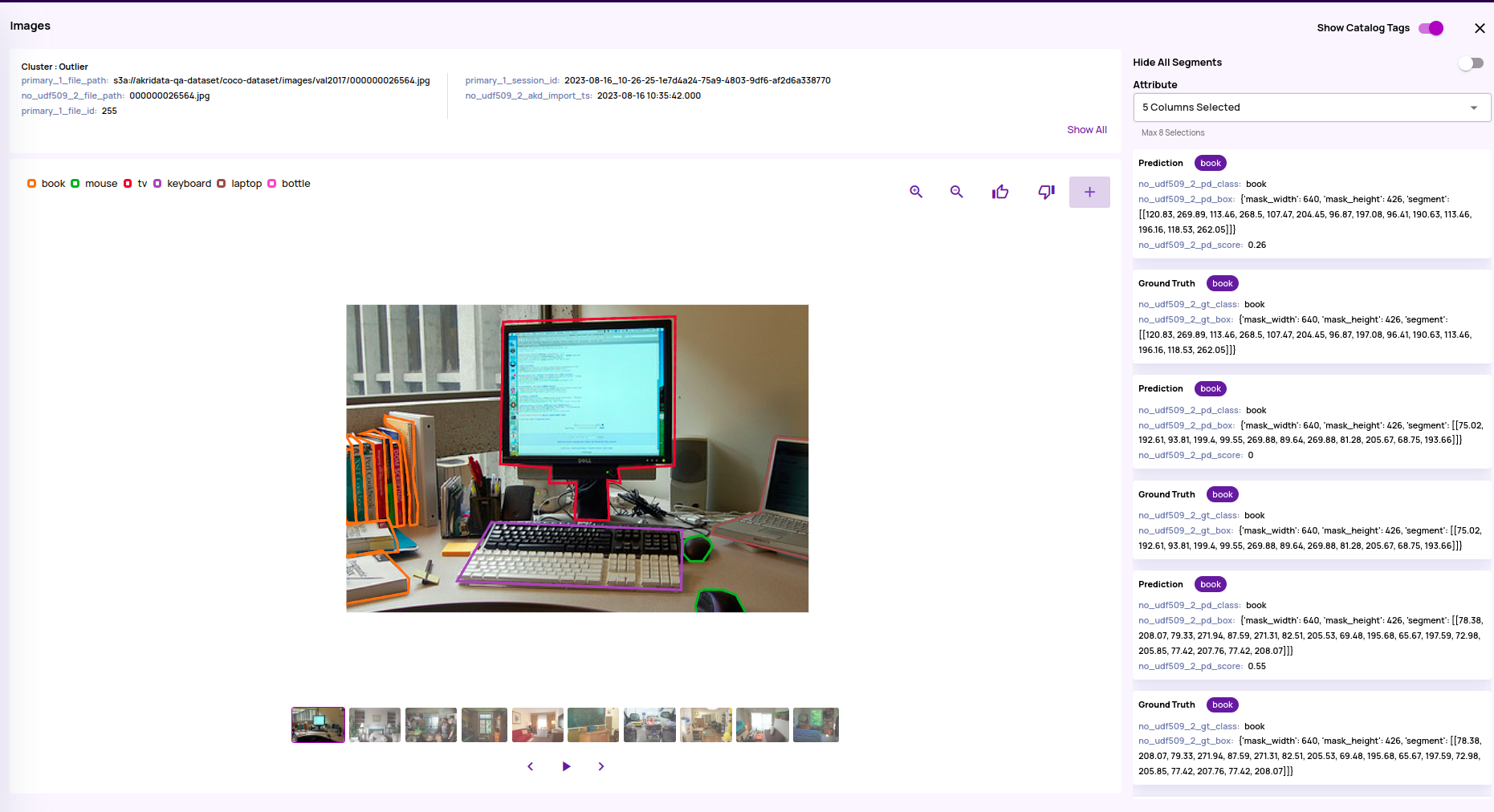
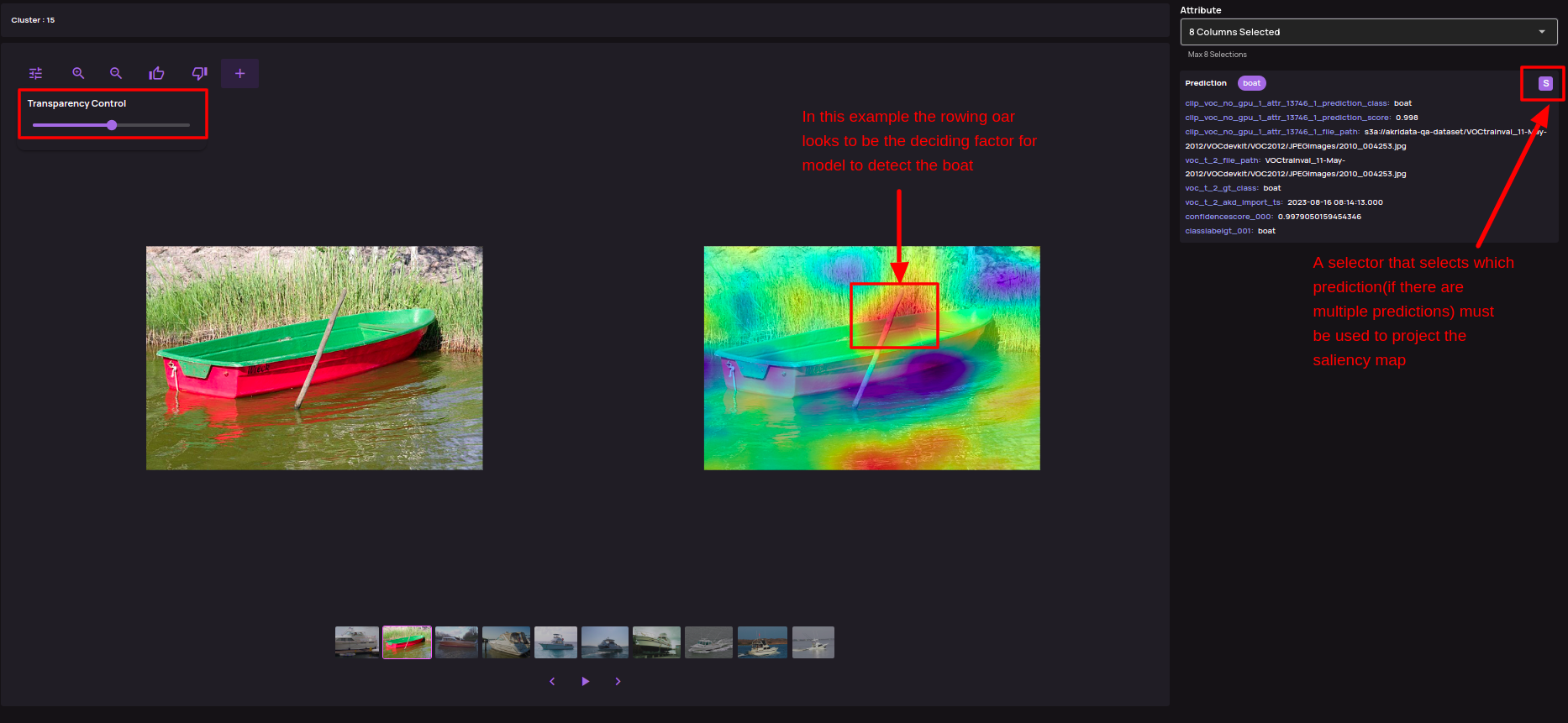
- Saliency maps for model inference interpretation(BETA): Saliency maps are a means to interpret the model inference results. With this release, Data Explorer brings saliency map generation and visualization as part of the 'Analyze Classification' type of job.
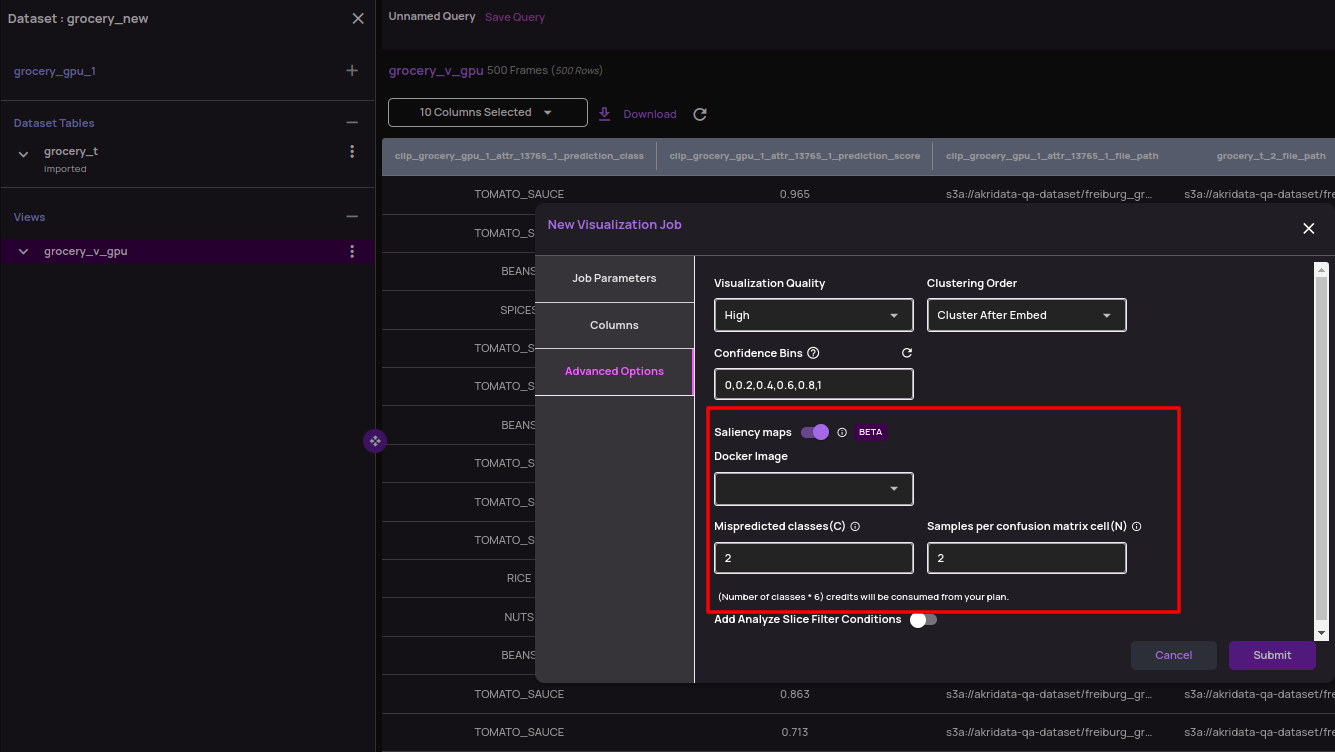
- During job submission of an Analyze classification job, saliency map options are specified as shown below. The implementation is based on a pluggable Docker Image for saliency map generation. Based on the parameters provided, saliency maps are generated on a subset of the images.
- The 'S' icon on the thumbnail indicates presence of saliency map.
- The saliency maps are visualized on the full-resolution image with a transparency control provided.
- During job submission of an Analyze classification job, saliency map options are specified as shown below. The implementation is based on a pluggable Docker Image for saliency map generation. Based on the parameters provided, saliency maps are generated on a subset of the images.
- Model Analyze job enhancements
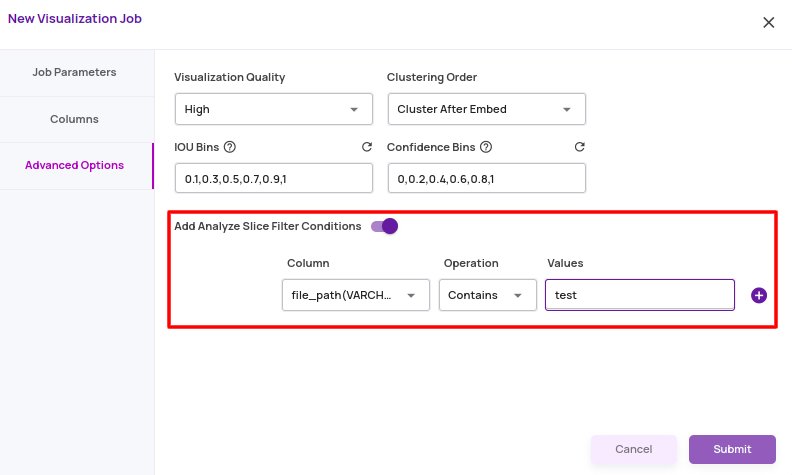
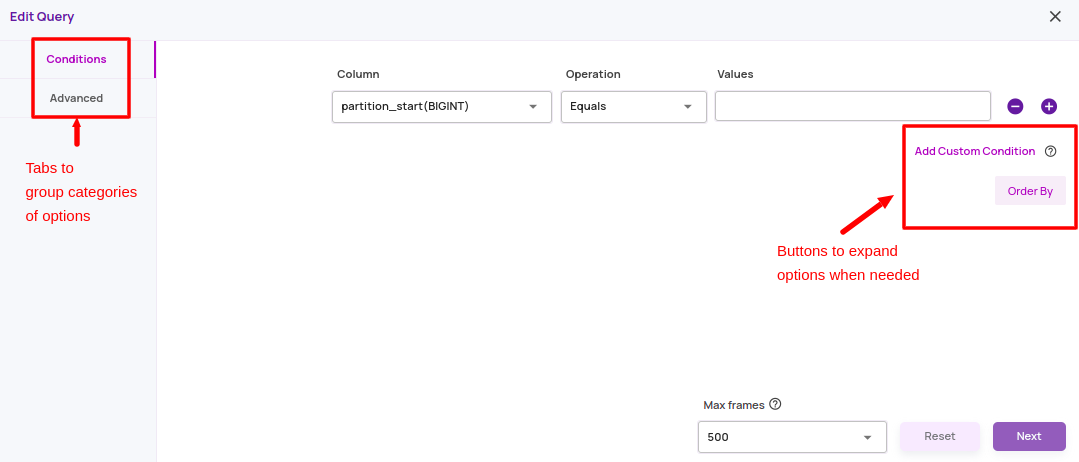
- Analyze Slice: A model analysis job takes an additional catalog filter condition as an 'analyze slice' specification. The analyze slice represents the subset of the images in the job on which model analysis statistics and visualization plots must be computed. In contrast, all the points in the job are available for search. A canonical use case of this capability is to create a job with all points in the dataset and
- Specify a 'test' slice for model analysis.
- View the confusion matrix and find some sample images where the model is weak.
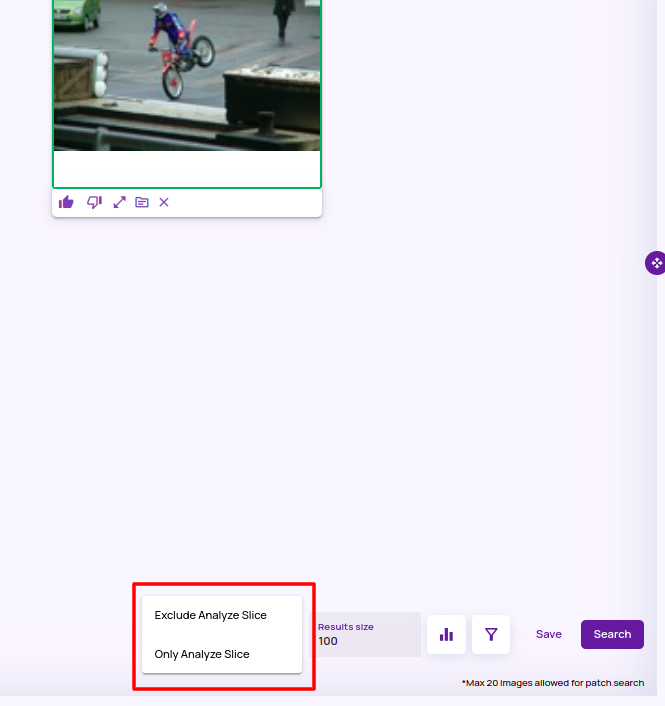
- Use similarity search to find more points similar to ii) from the entire dataset(including unlabelled images) with a filter 'Exclude analyze slice points'.
- Create a resultset from the results and send these for labelling.
- Choice of featurizer for plot generation: You can choose between a visual content-based featurizer or a model ground truth Vs prediction-based featurizer to produce the visualization plots.
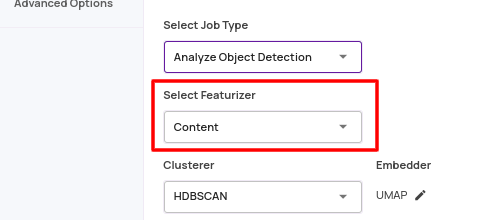
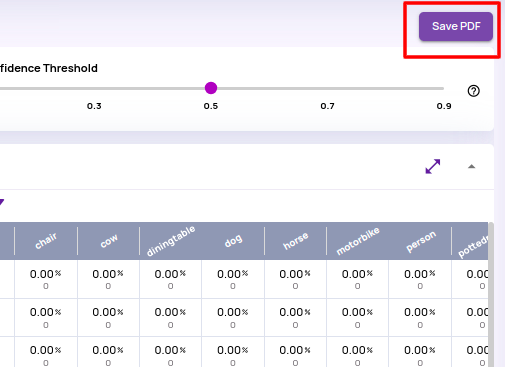
- Save PDF for analyze statistics view: You can export the analyze job statistics panel as a PDF for offline viewing and sharing.
- Analyze Slice: A model analysis job takes an additional catalog filter condition as an 'analyze slice' specification. The analyze slice represents the subset of the images in the job on which model analysis statistics and visualization plots must be computed. In contrast, all the points in the job are available for search. A canonical use case of this capability is to create a job with all points in the dataset and
- UI enhancements
- Dark mode
.png)
- Catalog page enhancements
- Dark mode
- Other enhancements
- Abort background jobs: A background ingestion job can be aborted from the Data Explorer Web UI.

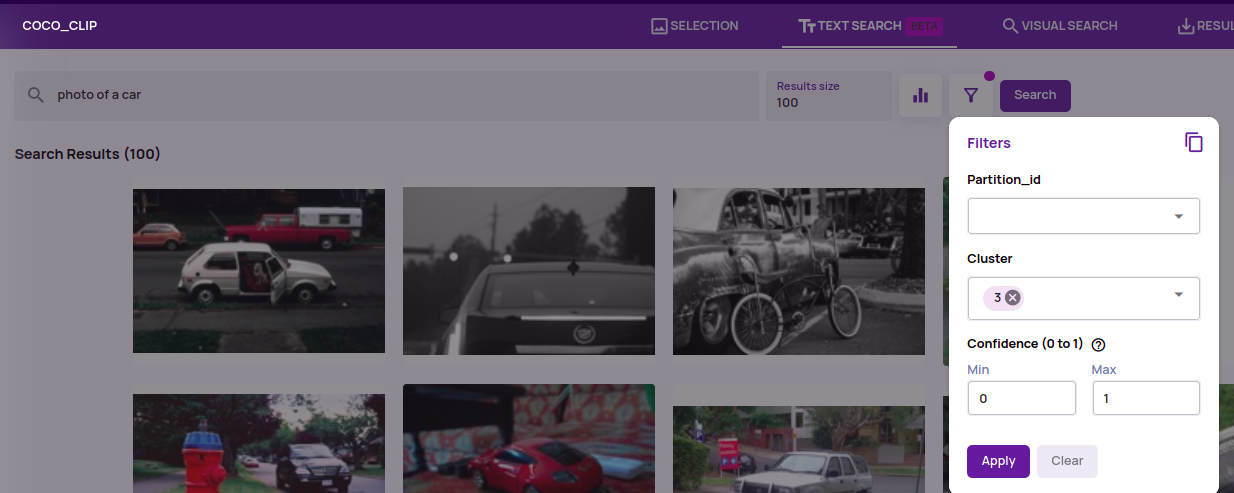
- Search space reduction options are provided in 'Text Search' on par with 'Visual Similarity Search'.
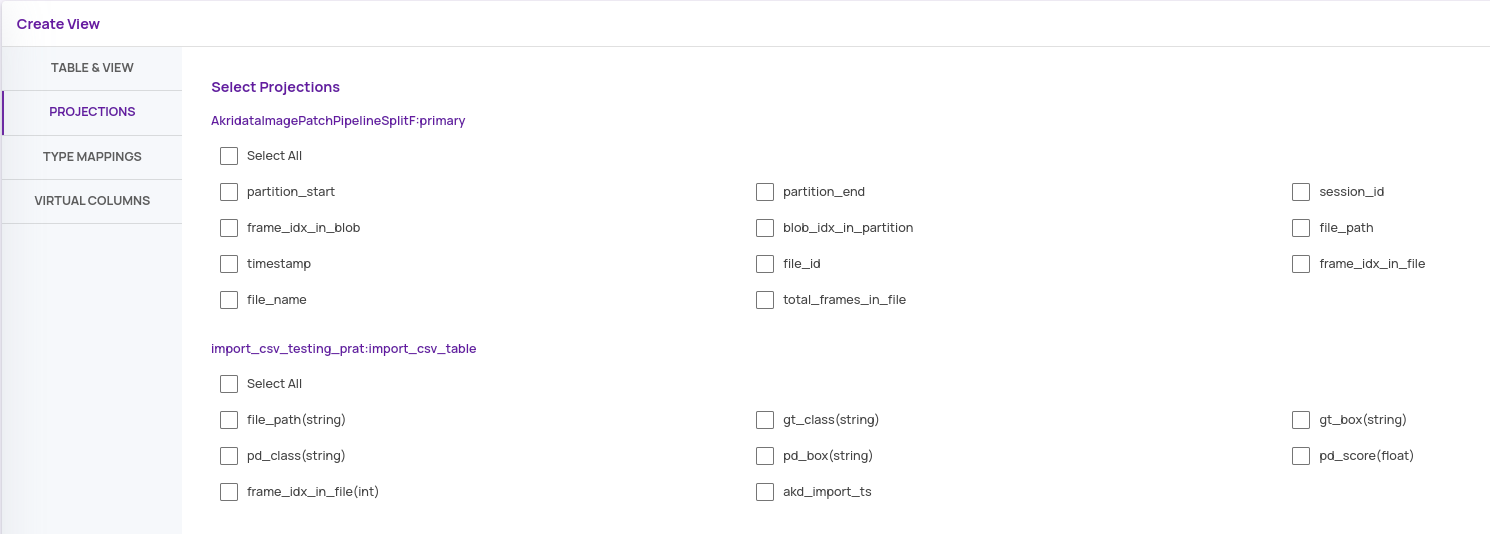
- Select a subset of columns when creating a view. By default all columns from the joining tables are selected.
- For video datasets
- A resultset dump from the resultsets UI page will have a relative timestamp within the video file against each frame in the resultset.
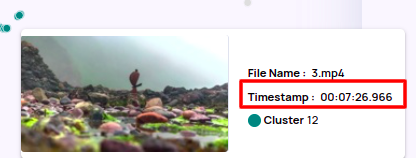
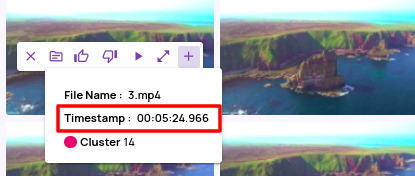
- A 'ts_in_video' column that captures the relative timestamp in the video file is available by default on the catalog page.
- The thumbnails show the relative timestamp in the file on hover and under 'Catalog tags' action button
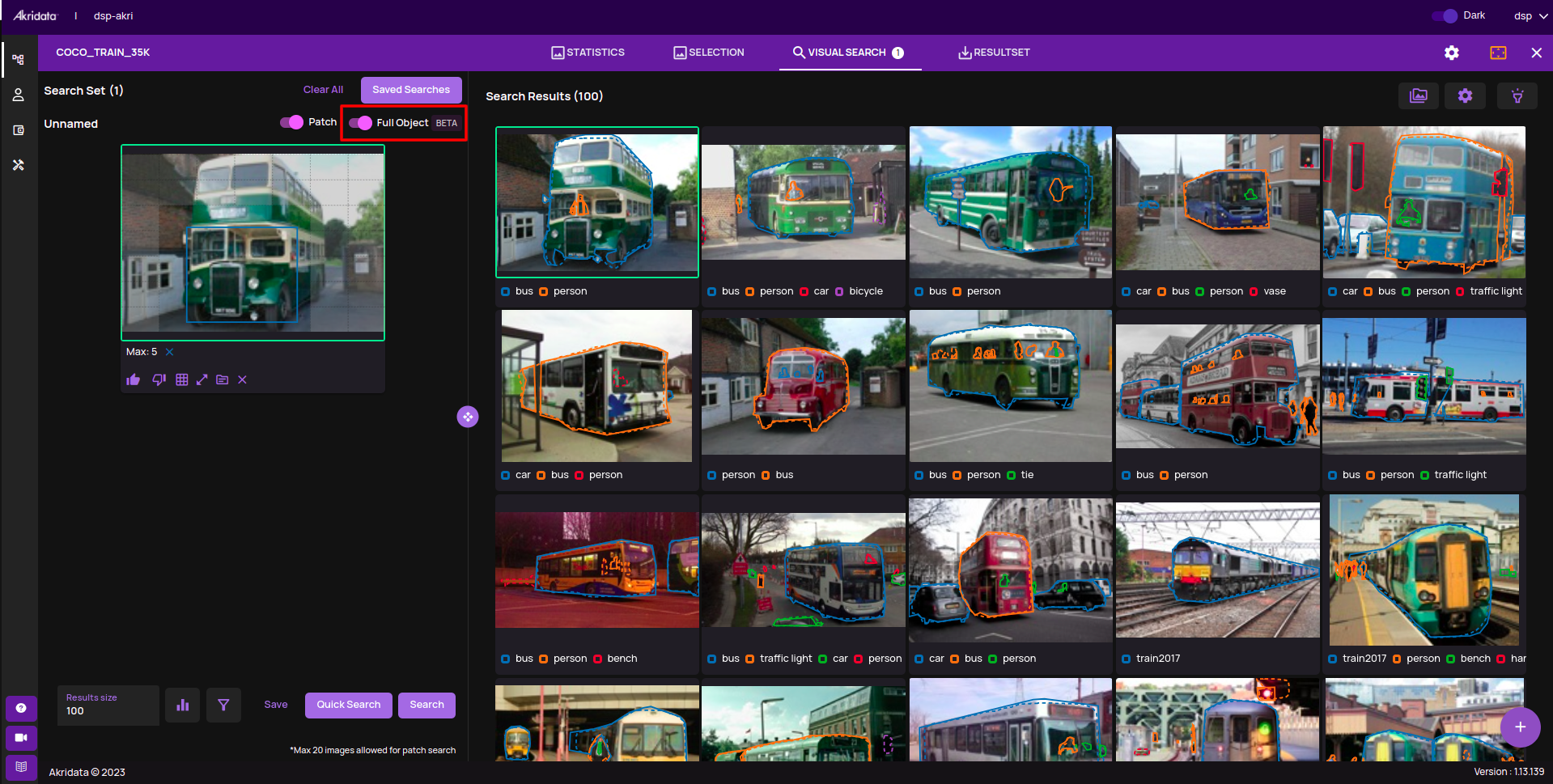
- The 'full object search' is through a new algorithm that provides higher accuracy through fast exhaustive search.
- Abort background jobs: A background ingestion job can be aborted from the Data Explorer Web UI.