Release 1.11.125 - June 4, 2023
- Enhancement to dump resultset contents on the Data Explorer web user interface(UI).
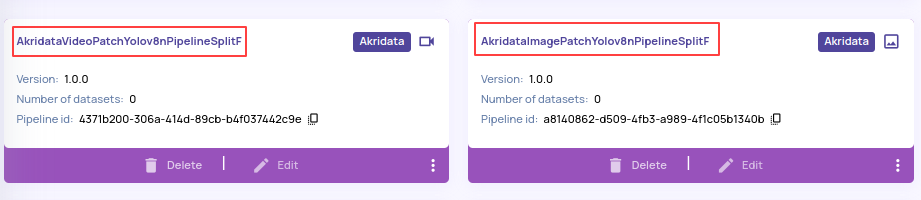
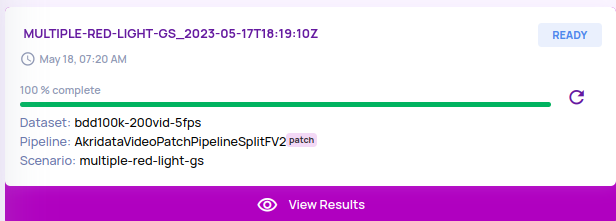
- Pre-registered pipelines with a Yolov8n-based object detector. These pipelines produce object detection information(class, bounding box with prediction confidence) into the catalog as part of data ingestion.
 The catalog produced has the following columns. This table can be joined with primary or other external tables to create views for visualizing the bounding boxes in explore jobs or create analyze jobs.
The catalog produced has the following columns. This table can be joined with primary or other external tables to create views for visualizing the bounding boxes in explore jobs or create analyze jobs.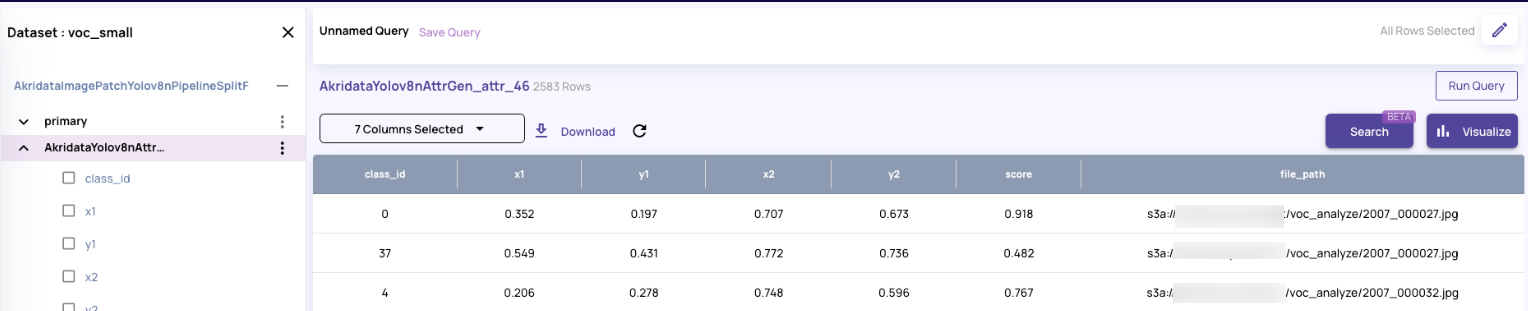 Note:
Note:
The above pipelines use the Yolov8n object detection model released under the GPLv3 license. If you are using these pipelines by attaching these pipelines to your dataset, then you are bound by the GPLv3 license terms and conditions.
The above pipelines are currently not supported by the Scheduled and On-demand ingestion policy. - Pre-registered docker image with Yolov8x-based object detector. This larger model is expected to give higher accuracy predictions but runs significantly slower than the Yolov8n object detector.
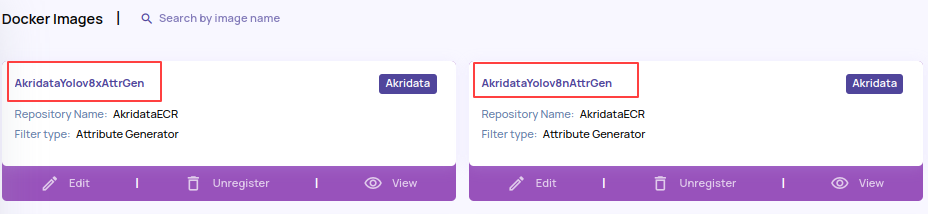 Note: The above docker images use the Yolov8x and Yolov8n object detection model released under the GPLv3 license. If you use these docker images to create pipelines and attach pipelines to your dataset, you are bound by the GPLv3 license terms and conditions.
Note: The above docker images use the Yolov8x and Yolov8n object detection model released under the GPLv3 license. If you use these docker images to create pipelines and attach pipelines to your dataset, you are bound by the GPLv3 license terms and conditions. - For an analyze job, the ground truth and prediction columns are available as grouping criteria by default in the plot view to allow coloring the plot view based on these fields. Additionally, a class gets the same color in the plot view for both ground truth and prediction columns.
- Global search user interface(UI) enhancements
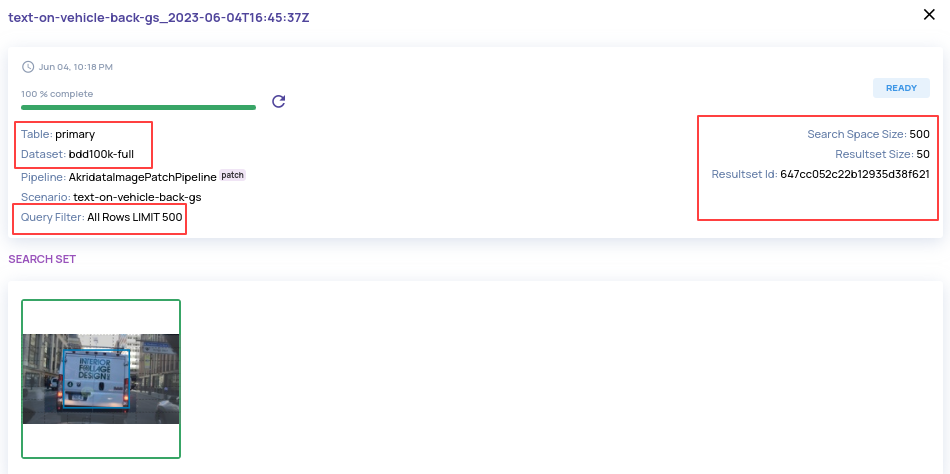
- Specify the number of results when submitting a global search.
- Additional information on the global search execution card, like catalog filter condition, size of search space etc.
- Support to install adectl in a proxied environment where external http/https traffic needs to be routed through a proxy.
- Addition of a new 'Starter plan' that allows starting small and buying additional data packs as the dataset sizes increase.
Release 1.11.107 - May 18, 2023
- Data Ingestion using managed resources(Background cataloging)(BETA): Before this release, ingesting(registering features) data into Data Explorer required you to provision a machine on which the adectl CLI would be executed. With this release, Data Explorer provisioned compute resources can be used to ingest your data. So, tell Data Explorer where your data is stored and start exploring in minutes!
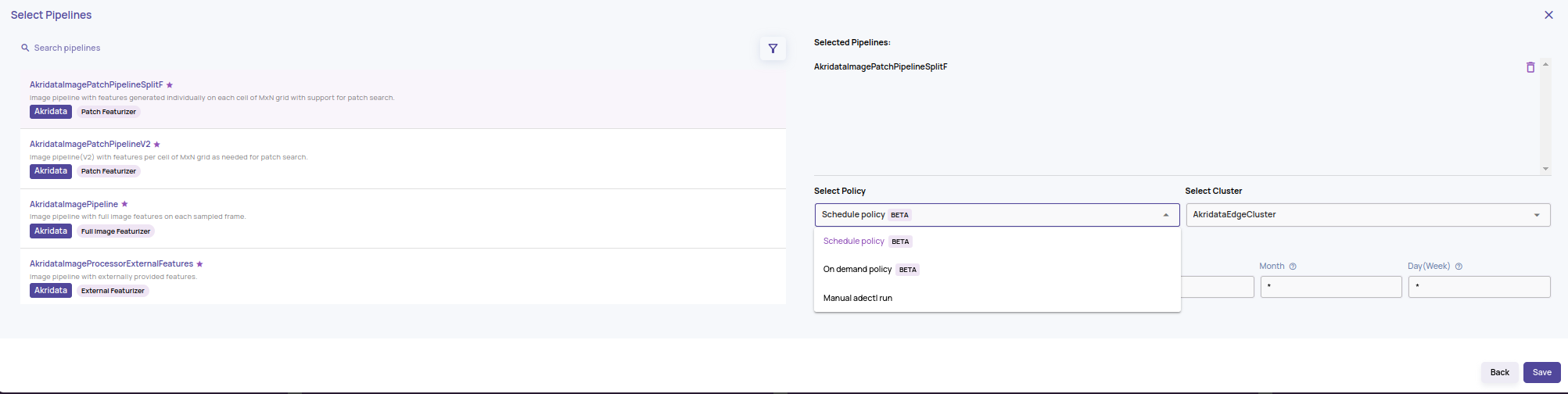 The attachment of a pipeline to the dataset has a 'policy' attribute with three possible values.
The attachment of a pipeline to the dataset has a 'policy' attribute with three possible values.- Schedule policy: Data ingestion will be triggered on a specified schedule, and Data Explorer will provide resources for the ingestion. This policy automates the data ingestion for cases where new data is coming into the data store(like an S3 bucket) regularly.
- On-demand policy: You can trigger data ingestion on-demand with a sub-directory provided as an argument, and Data Explorer provisioned resources will be used for ingestion.
- Manual adectl run: This mode allows data ingestion to be triggered through the adectl tool on compute resources provisioned by you.
- Global(Background) search(BETA): Before this release, the similarity search was available only within a job context. This similarity search is designed for interactive use, where you see the results and use thumbs-up/down buttons to refine the query and rerun the search. Global search augments this capability with the following characteristics.
- Run search as a background activity hence allowing it to scale to larger search spaces. In this release, Premium plan users can search in a search space of up to 500K images. This is expected to scale up further over upcoming releases, eventually allowing a search over the entire dataset.
- The search is more exhaustive and expected to produce better output, especially when matching results occur as a small percentage of the overall search space.

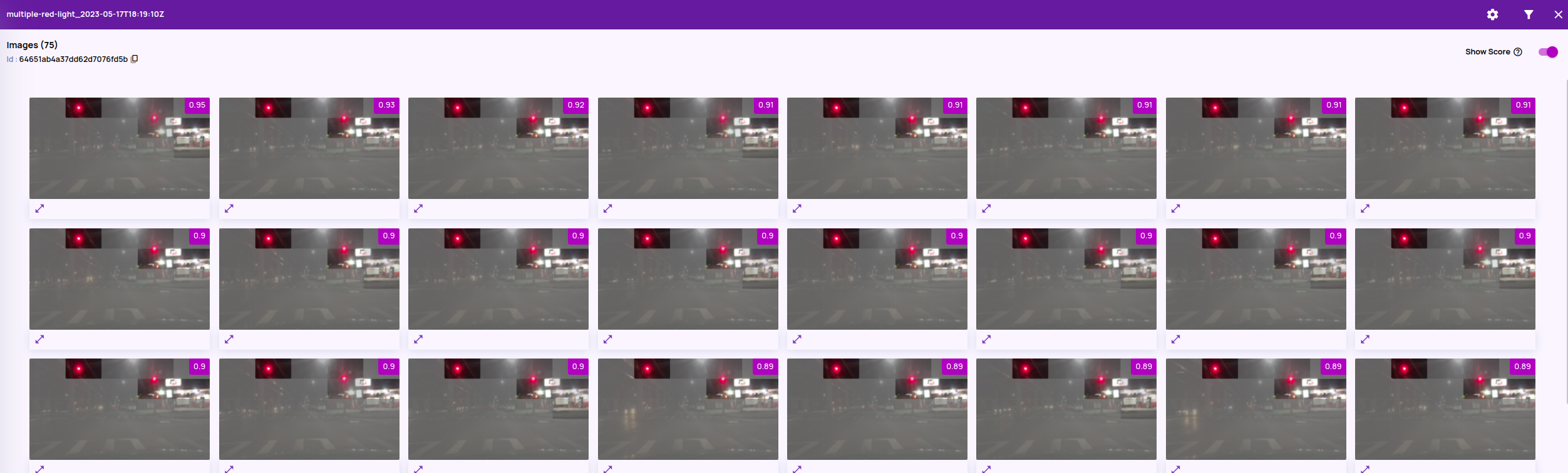
- Full object search(BETA): This is an additional patch search mode that matches the specified bounding box fully instead of treating the bounding box as a bag of patches to match. This is expected to yield more intuitive results when the full object in the bounding box is the target of the search.
- Patch search: Matching regions don't look for the full object(tree) but match parts of it at disjoint places in the image.
- Full object search: Matching regions look for the full object(tree)

- Patch search: Matching regions don't look for the full object(tree) but match parts of it at disjoint places in the image.
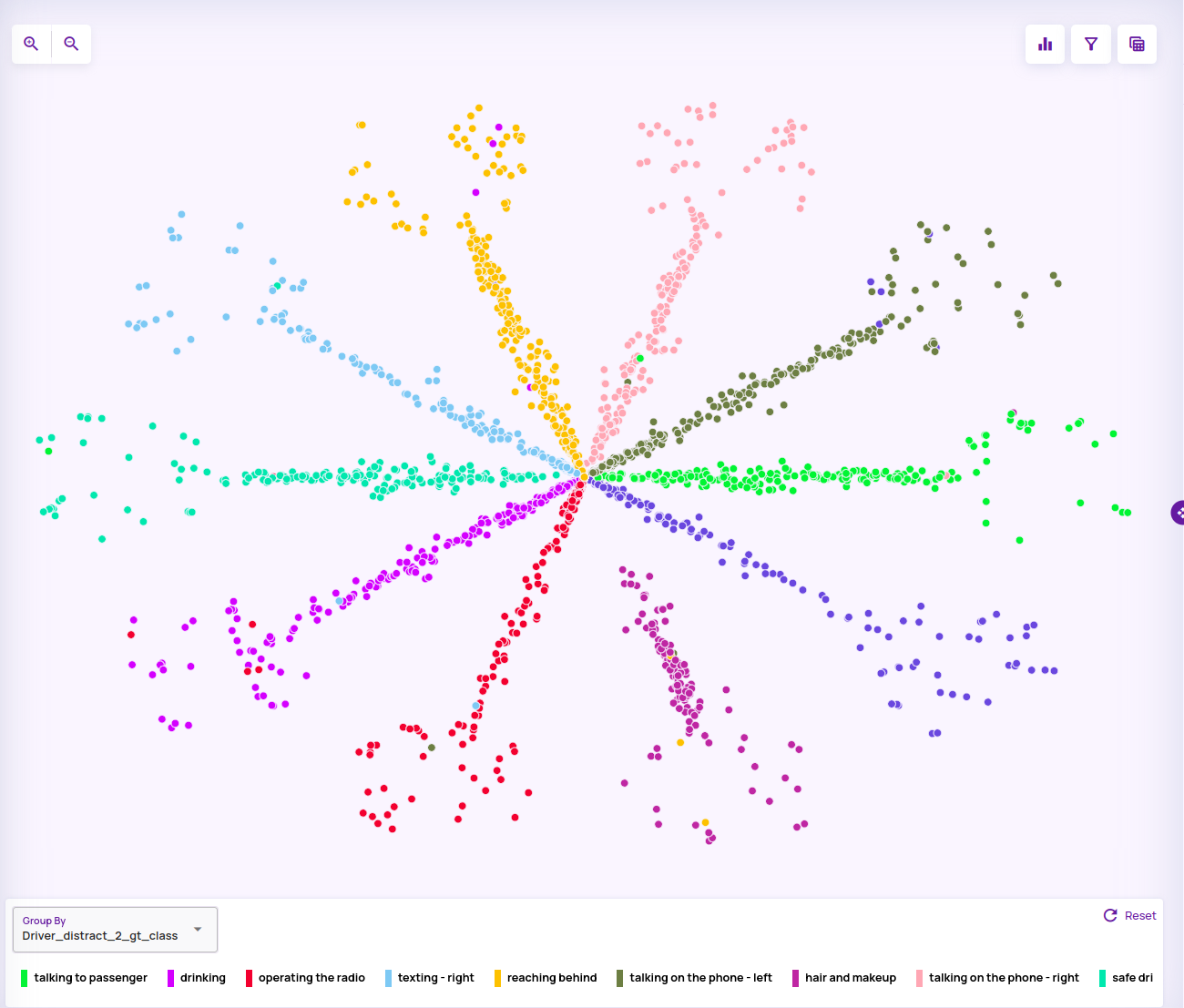
- Geometric class embedding for Analyze classification jobs: A new embedding type is introduced for analyze classification jobs that produce a plot view that is more easily interpretable. The spokes in the below visualization represent the ground truth classes, and the center of the plot represents high-confidence correct predictions with mispredictions towards the outer ends.

- Custom attributes as group-by attributes: Any categorical column can be imported as a criterion for applying group-by(colouring) on the plot view. The below example shows a group-by ground truth class in an analyze classification job.
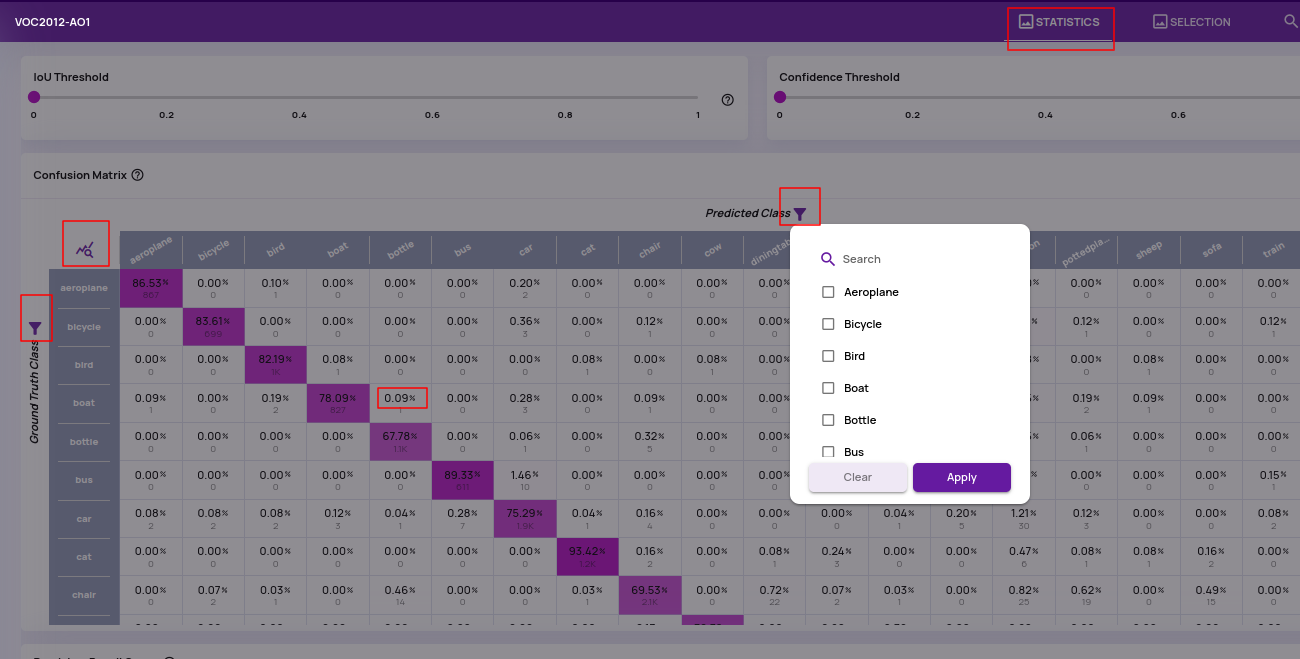
- Analyze job UI enhancements: The 'Statistics' is presented as a separate tab and set as the landing page for an analyze job. Additionally, interacting with the confusion matrix is enhanced through ground-truth and prediction filters, an expanded view for the confusion matrix and flexible screen space allocation for statistics.
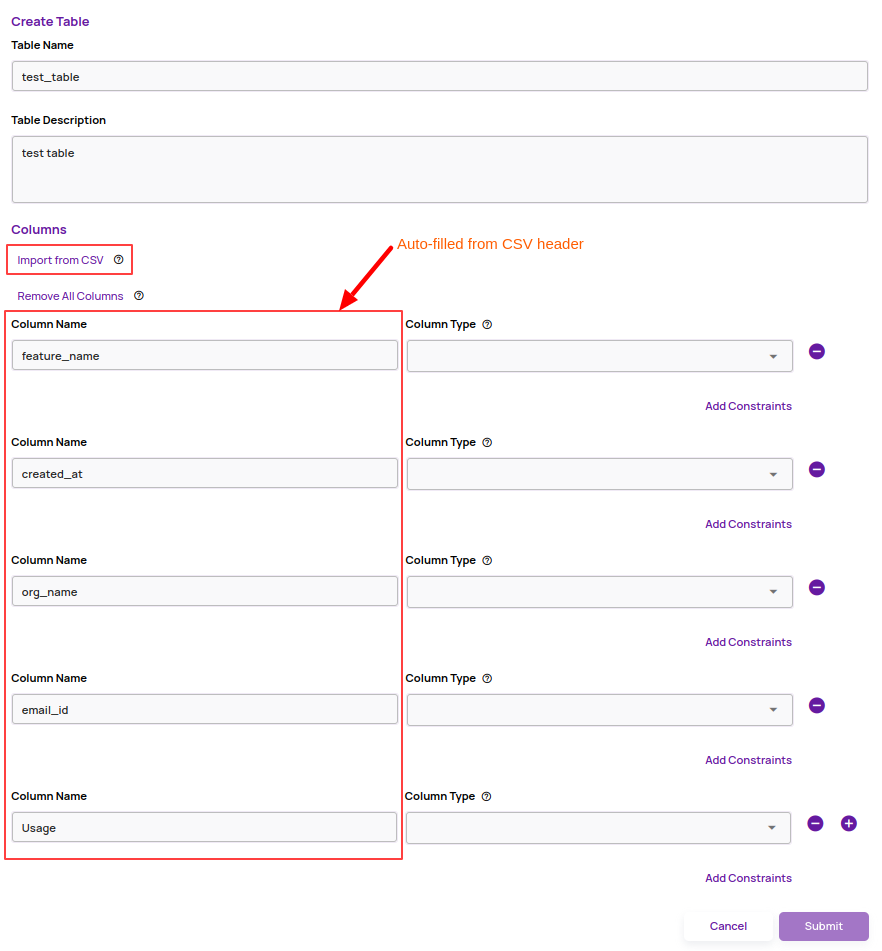
- Auto-fill column names for import CSV operation: The catalog import from a CSV file requires the creation of a catalog table, and the user experience for this operation is enhanced by importing the column names directly from the CSV file header.
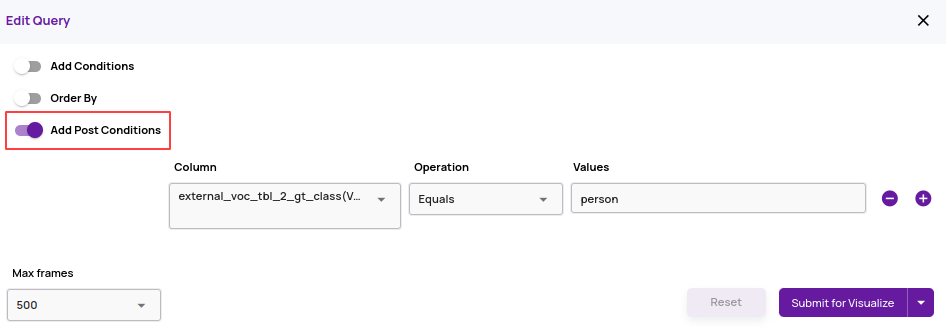
- Catalog POST conditions: If an image/frame has multiple rows in the catalog and the catalog query matches one row, then the default policy is to return all rows for that image. For example, suppose an image has two ground truth annotations, car and person, in a column named 'gt_class'. A catalog query condition with 'gt_class=person' will return both rows of the catalog. To override this default behaviour, an additional 'POST' condition can be specified to return only those rows that match the 'POST' condition. For example, the below POST condition will return only one row with 'person' ground truth annotation. A use case for this feature is to create a job with specific ground truth and prediction classes such that the exploration and analysis is more focussed with a smaller subset of object classes.