Training a deep learning model is an iterative process, and each iteration requires the identification of areas of weakness in the model and retraining the model on relevant data that will improve or eliminate the area of weakness. The model analyze feature allows intuitive and efficient identification of areas of model weakness through visual presentation and interactive statistical panels to help identify data samples matching the model weakness areas and search for more samples to build a curated training set. The following are the main capabilities available.
Visualize clusters based on model ground truth versus predictions.
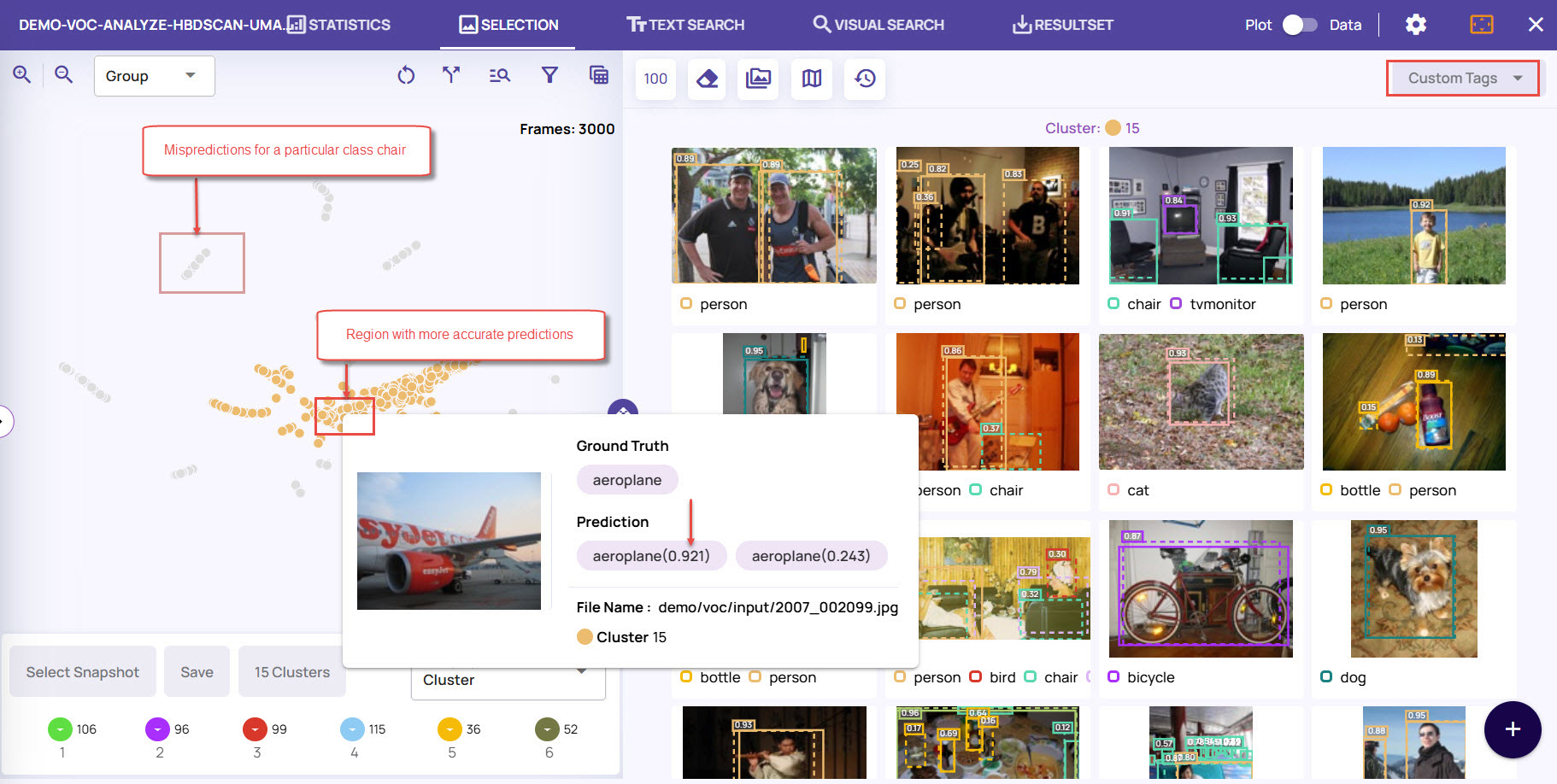
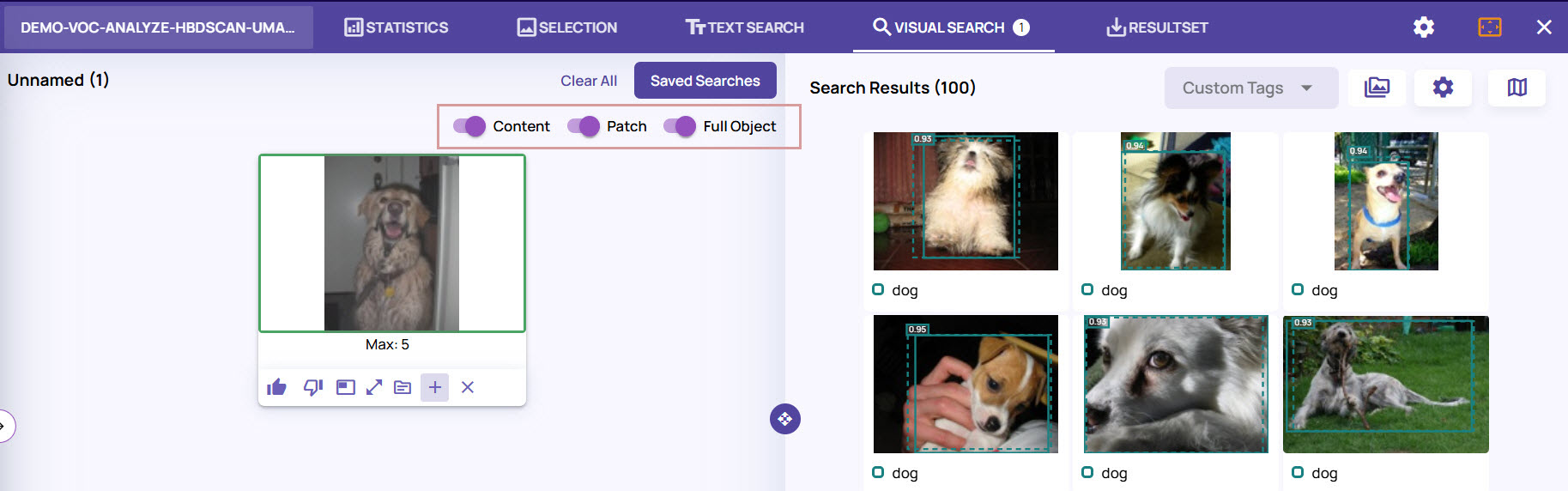
Visualize clusters in one dimension and similarity search in a different dimension. For example, let us say, based on model performance, we have a cluster of mispredictions where class A is predicted as class B. To build a dataset with more similar-looking samples, you can use a content-based similarity search to find similar-looking samples.
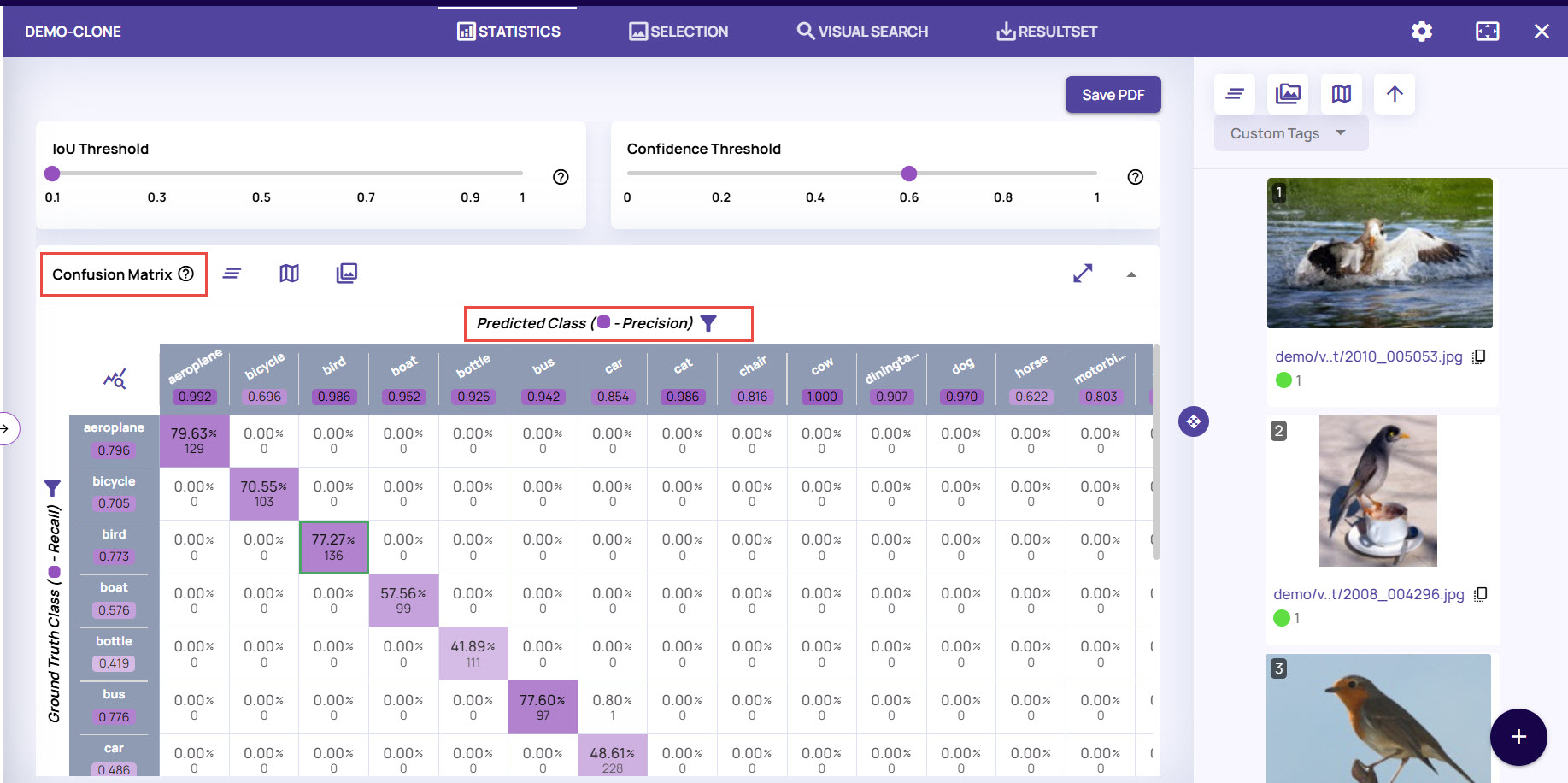
Interactive confusion matrix, precision-recall curve and IOU Vs confidence histograms to drill down into model performance.
.jpg)
The model analyze feature is available for classification, object detection, and instance segmentation models.