This release introduces the creation of a custom pipeline that will be executed as part of ingesting data using the 'adectl run' command. A data processing pipeline consists of the following modules.
- Preprocessor: Any processing on the image/frame before feeding to the featurizer.
- Featurizer: Featurizes each image/frame, typically using a deep neural network(DNN).
- Thumbnail generator: Generates a compact representation of the image/frame that will be displayed on the Data Explorer UI.
- Attribute generator: Generates a CSV file with attributes for each image/frame, and these attributes will be ingested into the Data Explorer catalog. There can be more than one attribute generator attached to a pipeline.
The custom pipelines allow the construction of a pipeline with one or more of the above modules provided by the user in the form of a docker image that complies with the data input/output interface expected from each module. Some use cases that can be achieved with this support are as below:
- Bring your own featurizer that is tuned for your dataset.
- Domain-specific pre-processors that improve the behaviour of the featurizer.
- Custom logic to extract attributes from each image/frame. For e.g., a lens dirt detection program can be packaged as an attribute generator docker, and the result of this program will be stored by Data explorer as an attribute against each frame/image that is available for querying and joining with other internal and external catalog tables.
To achieve the above, this release introduces three new entities.
- Docker repositories: A docker repository hosted at Dockerhub or AWS ECR(Elastic Container Registry) that is owned and managed by your organization.
- Docker Images: A docker image that provides a preprocessor, featurizer, thumbnail generator or attribute generator functionality. Data Explorer comes with a few docker images out-of-the-box that is sufficient for most general use cases and can be identified by the 'Akridata' badge highlighted below.
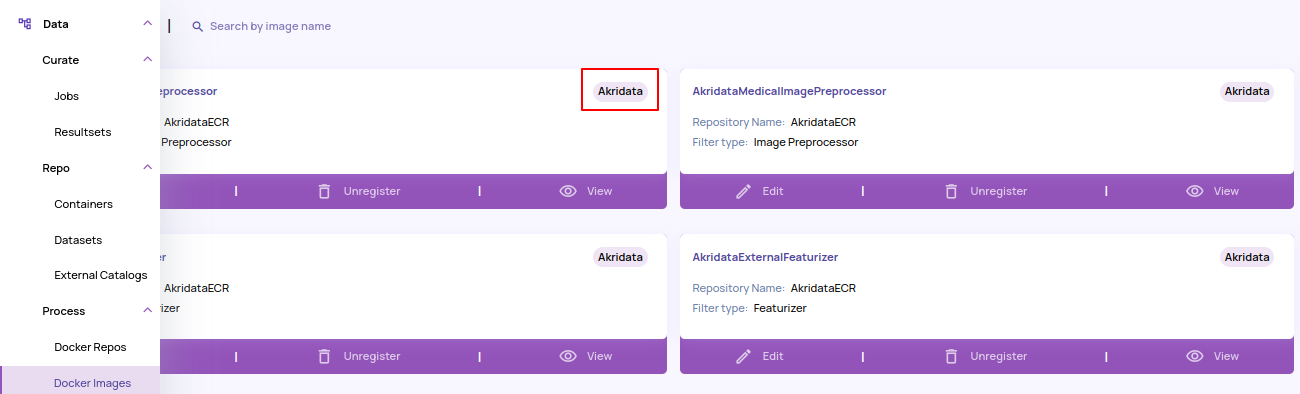
- Pipelines: Data Explorer provides a few pipelines for both video and image data types out-of-the-box that is sufficient for most generic datasets and can be identified by the 'Akridata' badge highlighted below. Certain pipelines have been replaced with better versions and hence marked as 'Deprecated', implying that they will not be available for attaching to a dataset.
Multiple pipelines
You can attach more than 1 pipeline to a dataset and visualize based on the catalog produced by each pipeline individually.
With the above constructs, a typical flow expected is as below:
- The organization admin provisions a docker repository as a one-time operation.
- The users package their custom processing modules as docker images and upload them to their organization-provisioned repository.
- The users define a pipeline by selecting Data Explorer provided or custom pre-processor, featurizer, thumbnail generator and optionally one or more attribute generators.
- The users attach the pipeline to a dataset and run 'adectl run'. The same pipeline can be attached to more than one dataset, thus allowing reuse of pipelines.