Release 1.17.154 (Bugfix release) - June 08, 2024
- Fix for an issue where data ingestion from a storage bucket in an Azure storage account with Hierarchical namespace enabled was hanging.
Release 1.17.153 (Maintenance release) - June 03, 2024
- For setup with data registration through the adectl command line tool, an image server docker is available to act as a gateway to full-resolution images from the local machine/on-prem network to Data Explorer. Please contact Akridata support for more details on whether this is applicable to your deployment.
- akride SDK enhancements to support video files and utilize GPUs.
- Confidence threshold as a job parameter for Autolabel classification jobs.
Release 1.17.140 (Maintenance release) - May 14, 2024
- Sequence search improvements
- Frames per sequence increased from 10 to 30.
- Improved search procedure to provide better accuracy.
- Autolabel quality improvements.
- Support for Union Views for the following use case
- Suppose an image has 5 ground truths and 6 predictions that have been imported into 2 different tables, namely gt_tbl and pred_tbl.
- To visualize the ground truths and predictions, the above tables must be joined with a pipeline primary table. A view with (primary JOIN gt_tbl JOIN pred_tbl) will result in a view with 5x6 = 30 rows which is not the intent here.
- A Union View allows specifying a view that is (primary JOIN gt_tbl) UNION ALL (primary JOIN pred_tbl) that appends the rows of the first JOIN to the rows from the second JOIN resulting in 5+6 = 11 rows as intended.
- Support PyTorch-YOLO as an additional format in import catalog operation.
Release 1.17.118 (Bugfix release) - April 25, 2024
- Fix a bug where text search was not enabled on a job.
- Fix a bug where fetching details for a catalog view with an external catalog table fails.
Release 1.17.116 - April 24, 2024
- Visual catalog: Visual mode as an additional mode of presentation for catalog results



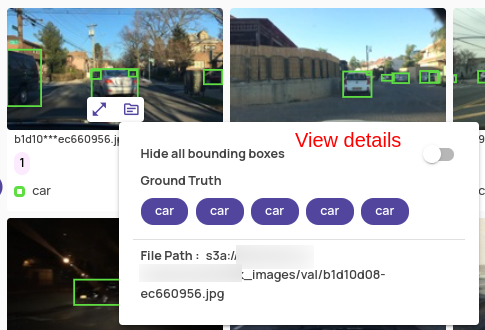
- Autolabel enhancements: Over the base feature described in Release 1.16, this release brings in the following enhancements.
- Labeling Spec enhancements
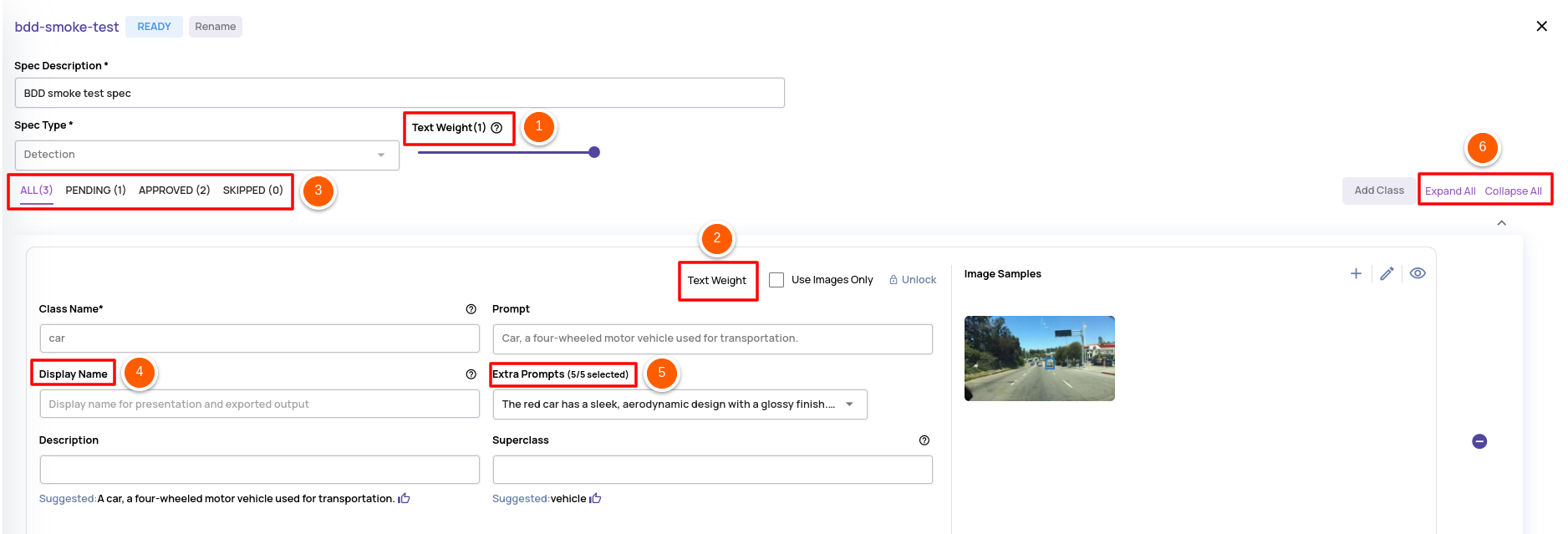
- Choose a spec-wide weightage for text prompts versus image prompts(samples).
- Override the spec-wide weightage for text prompts with a different value specific to a class.
- Organize the classes based on their approval status into different tabs for easier navigation and focus.
- Have a separate display name field different from the class name. The display name is an alias used for display purposes, and a typical scenario for usage is described below.
- Suppose speed20 refers to a class for speed signs of 20mph in your dataset.
- 'Speed sign 20' is better interpreted by LLM than speed20, so the class name for this case must be set to 'speed sign 20' while the display name must be set to 'speed20'.
- Up to 5 extra prompts describing the class's visual characteristics can be selected to convey additional information to the autolabel models and improve accuracy.
- Collapsed mode for each class to improve navigation and focus on one class at a time.
- Additional ways to provide image samples
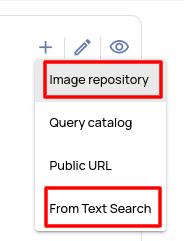
- Picking from images uploaded to an image repository.
- Through text search
- Additional job submit parameters to tune autolabel behaviour
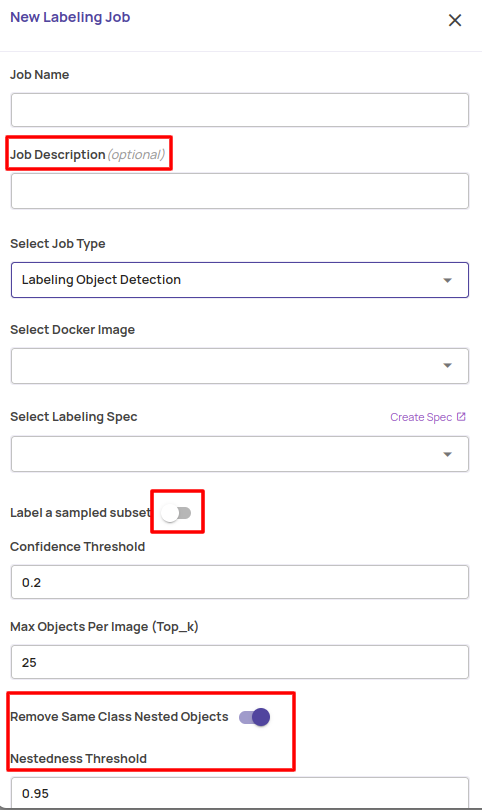
- A job description field to capture more descriptive information on the purpose of the job. This is commonly available for all jobs.
- Autolabelling a coreset sampled subset for quick experimentation runs.
- Nested object detection and automatic removal parameters
- Additional filtering and grouping fields in the labeling statistics panel.
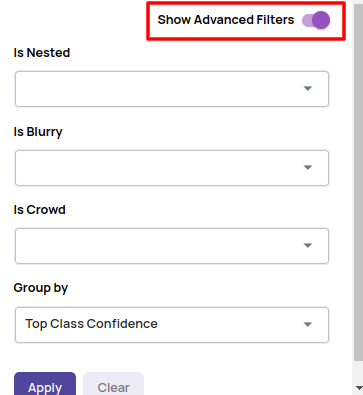
- Accept/Reject single annotation in addition to bulk actions.
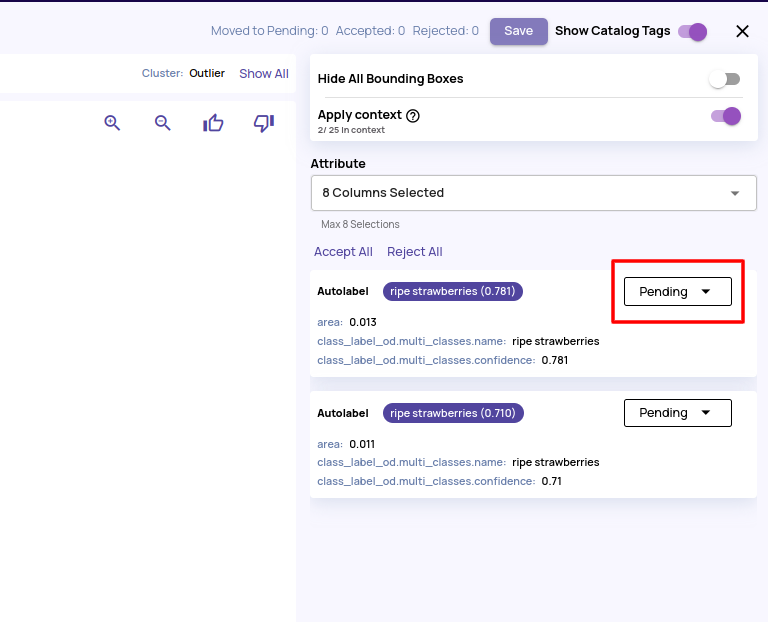
- Download the autolabel resultset in COCO format in addition to JSON.
- Labeling Spec enhancements
- Other enhancements
- Apply a resultset filter on catalog query output enabling creating a new job with points in a resultset or some subset of points in a resultset

- The following additional formats are supported for Import catalog operation.
- Yolo Darknet
- Yolo V8(Ultralytics)
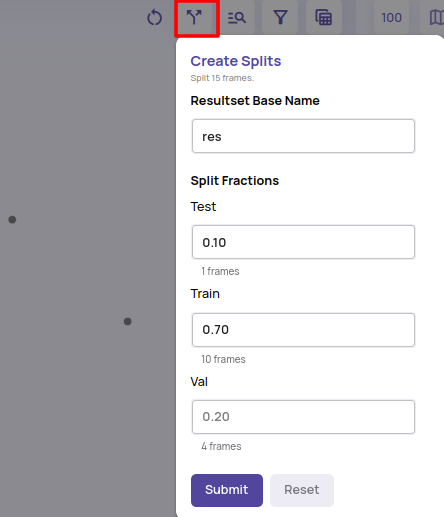
- Single button creation of (train, valid, test) splits within a job.
- Improved user experience on full-resolution image view, with the ability to navigate through all images in context, pagination, and lower latency due to pre-fetching of all images on a page.

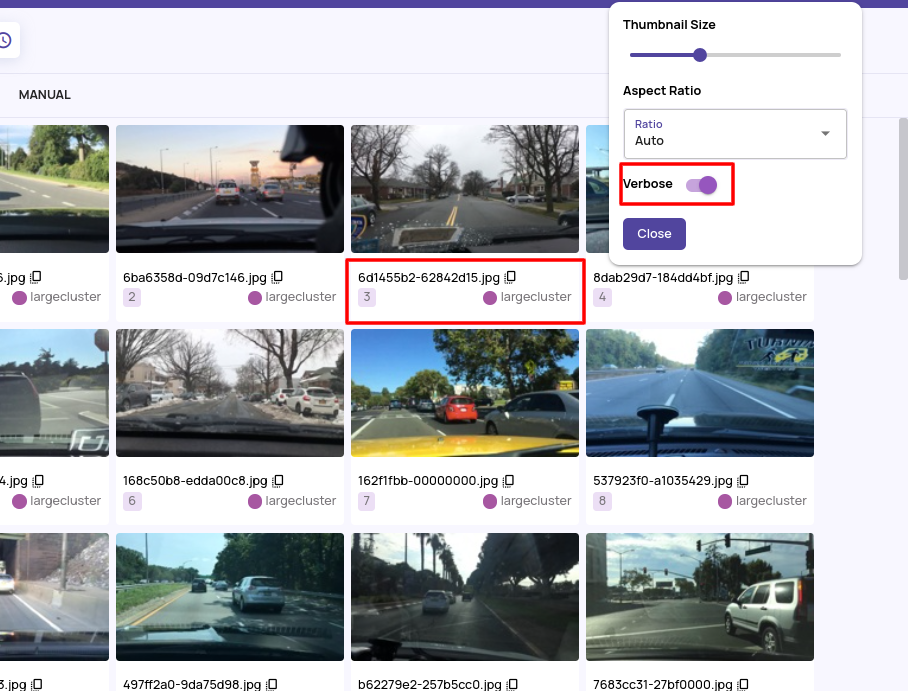
- Verbose mode for thumbnails in a job that shows key information inline below the thumbnail
- Improved score calibration for text search results. In previous releases, the good Vs. bad results did not have discriminative scores due to underlying model behavior.
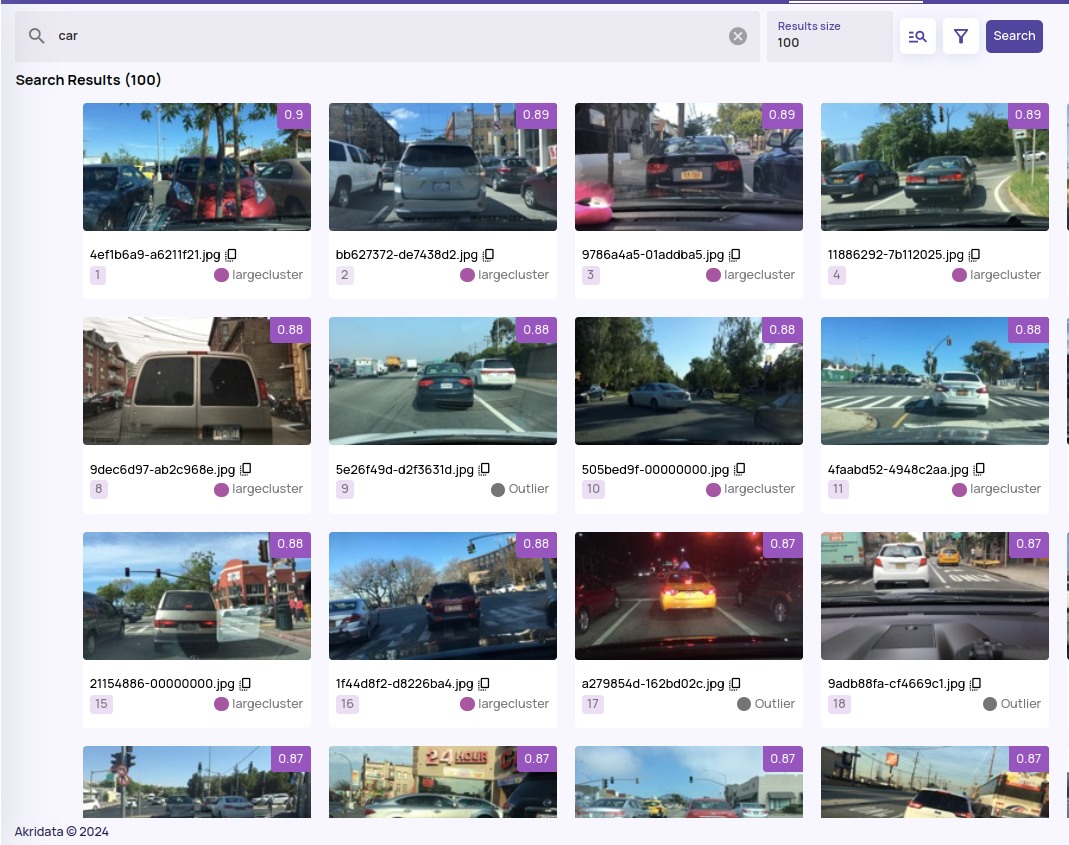
- Public dataset import enhancements
- 1 public dataset imported automatically for a new account signup.
- Jobs created with text search support
- Catalog view edit support to add new tables, add virtual columns etc.
- An additional description field is added to the resultset and jobs to capture more descriptive information that can be used for search.
- Basic support for DICOM format files.
- Apply a resultset filter on catalog query output enabling creating a new job with points in a resultset or some subset of points in a resultset
Notes
- In 'Visual search', the 'Quick Search' option has been removed, and the 'full object' search is defaulted.