As described in the Register dataset article, you can attach pipelines to the dataset when the dataset is created. This article describes the steps to attach and detach pipelines after the dataset is successfully registered.
Access Pipeline Operations
On the dataset main page, click the dataset card for which you want to perform the pipeline operations.
.jpg)
On the page for the selected dataset page, click the 3-dots icon adjacent to the Catalog button, to open the drop-down.

Select Pipelines.
Using this menu option, you can execute existing pipelines, attach a new pipeline to the dataset, or detach an existing pipeline from the dataset.
Execute Pipelines
This option enables you to ingest the selected pipeline into the dataset.
On the dataset main page, click the 3-dots icon, select Pipeline > Execute pipelines.
.jpg)
The Ingest Now window opens displaying the Base URL of the pipeline. This field is not editable.Enter the subdirectory path.
You can leave this field blank to ingest all data, provide path to the subfolder from where the data should be ingested.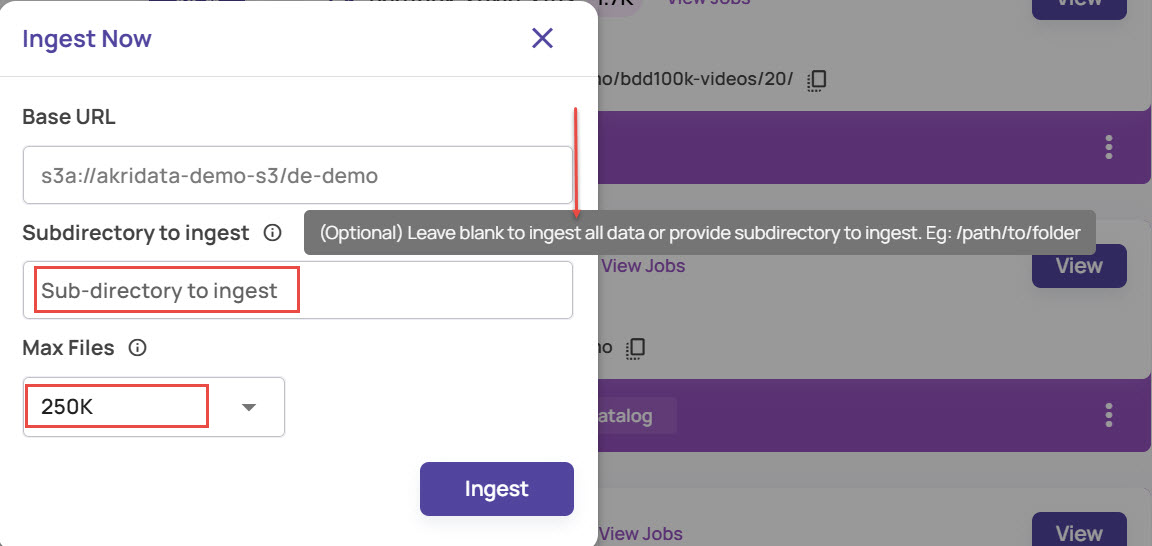
Select the maximum number of files that should be ingested.
Click Ingest.
The application initiates the process of ingestion.
Attach Pipeline
Select Pipeline > Attach pipelines.

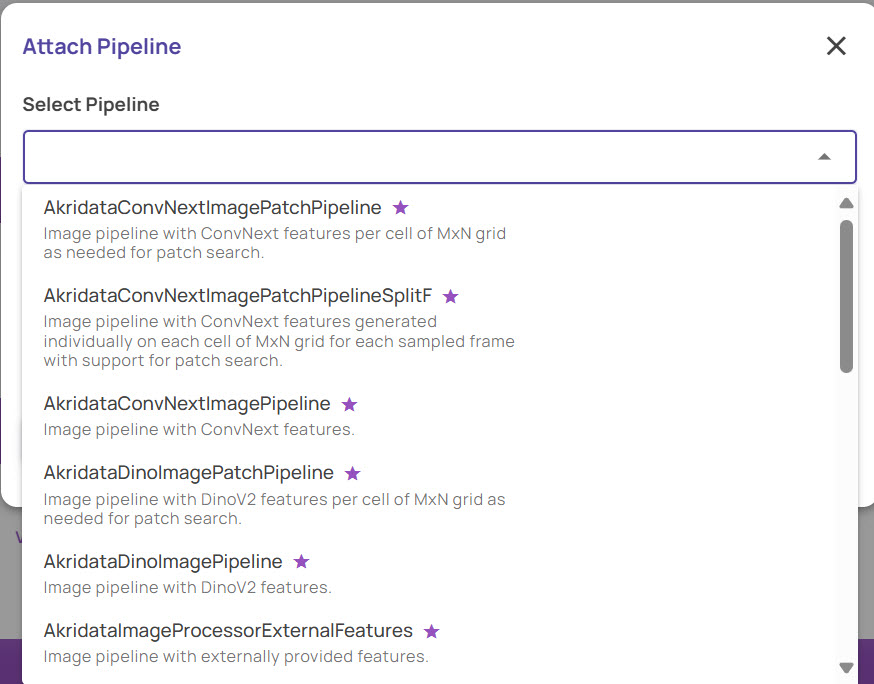
In the Attach Pipeline screen, select the pipeline from the drop-down of available pipelines. The 'starred' pipelines are the recommended pipelines.
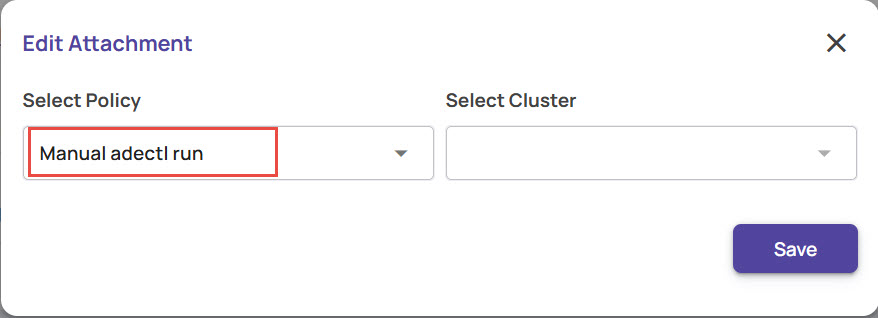
Select the policy for this attachment that determines the mode(scheduled Vs triggered) of ingestion and the compute resources where ingestion will be done.
Schedule policy(BETA): The ingestion will be triggered as per the provided schedule on the selected cluster. Currently, only one pre-provisioned cluster, 'AkridataEdgeCluster', is available for selection, and this list will be extended with user-registered clusters in the future. The schedule is specified using a cron string.
On-demand policy(BETA): In this mode, the ingestion is triggered by the user as needed on the selected cluster.
Manual adectl run: In this mode, the compute resource for ingestion is to be provisioned by the user and ingestion must be triggered using the adectl command line utility.
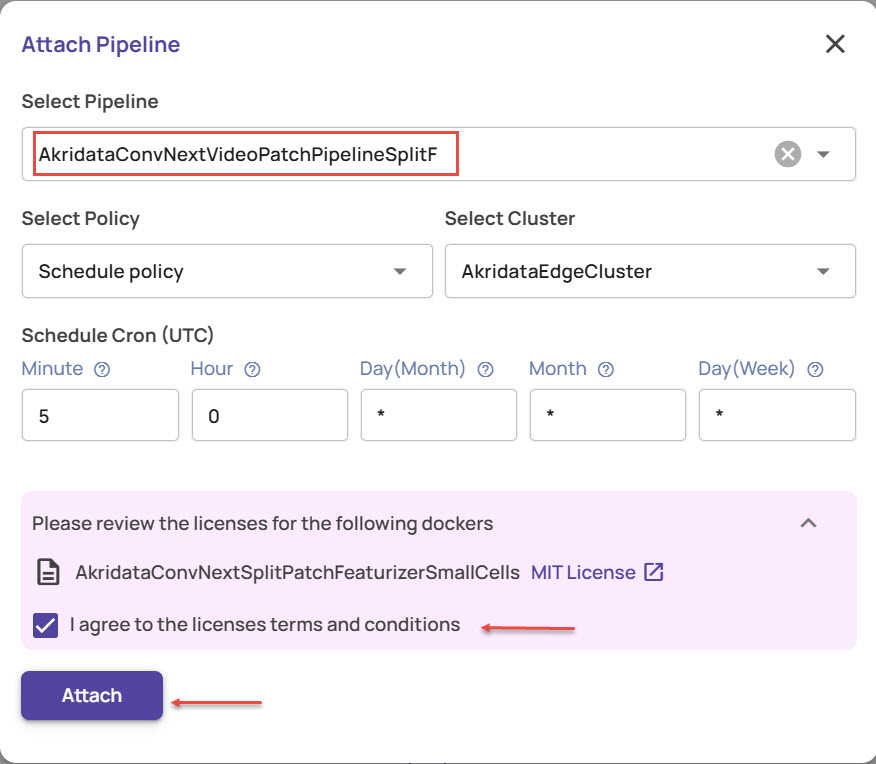
Click the Attach button.
View pipeline attachment details
The list of attachments for a dataset can be viewed on the dataset details page.
Click the dataset card to open the dataset page.

On the dataset page, click the PIPELINE tab.
This displays a list of all pipelines attached to the dataset, the featurizer type and the corresponding policy attached to the pipeline.
Operations on pipeline attachments
Under the Actions column, you can perform the following:
For Schedule and On-demand policy attachments, click the View Details arrowhead as shown below to view details of the last executed ingestion session that was scheduled or triggered by the user. The details section shows the progress percent (for in-progress sessions) and other details.
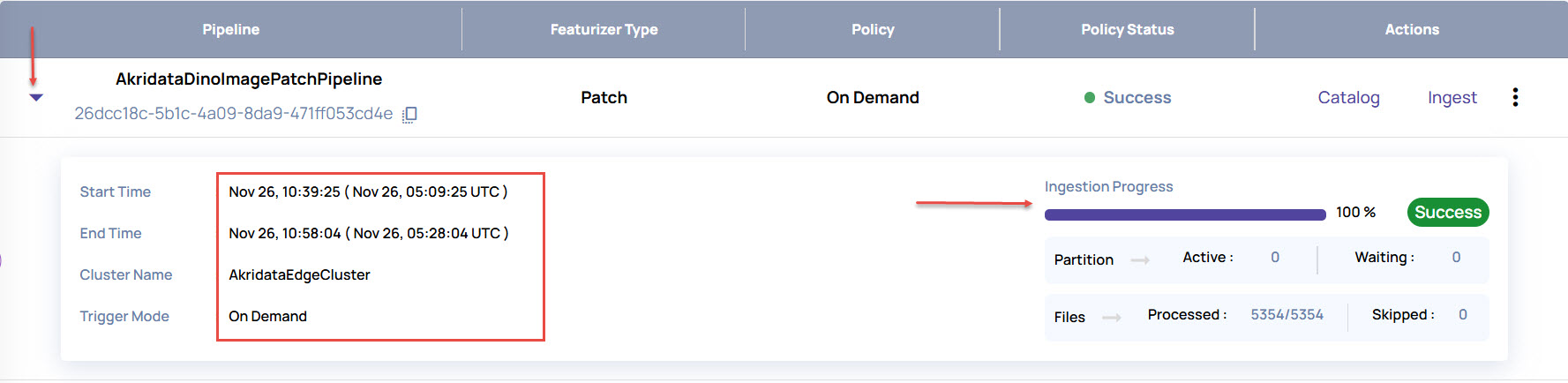
Click Catalog to view the catalog for the pipeline.
For Schedule and On-demand policy attachments, click Ingest to execute the pipeline as per the base URL.
You can select the sub-directory and maximum number of files for ingestion.Click the 3-dots icon to perform the following:
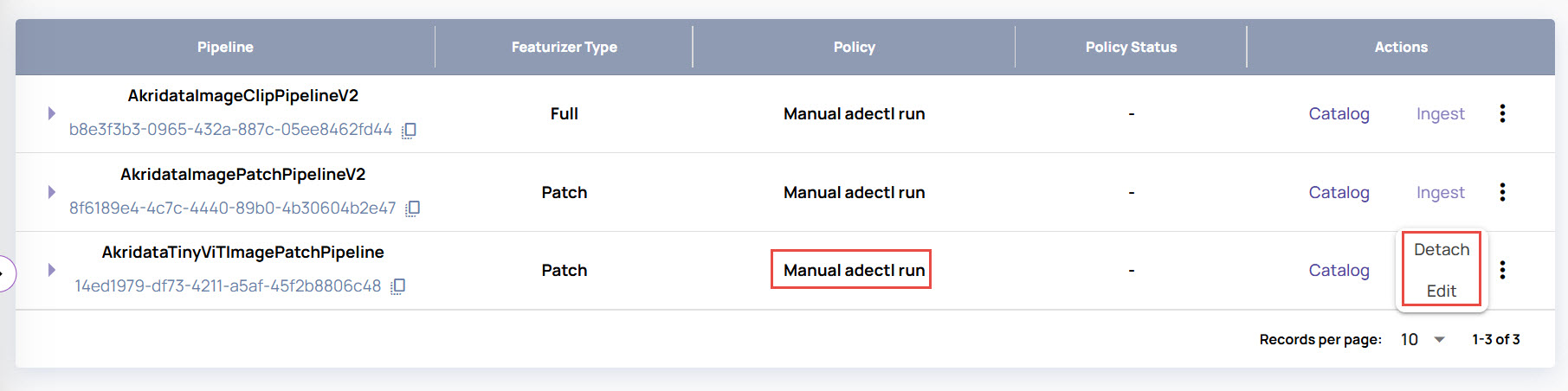
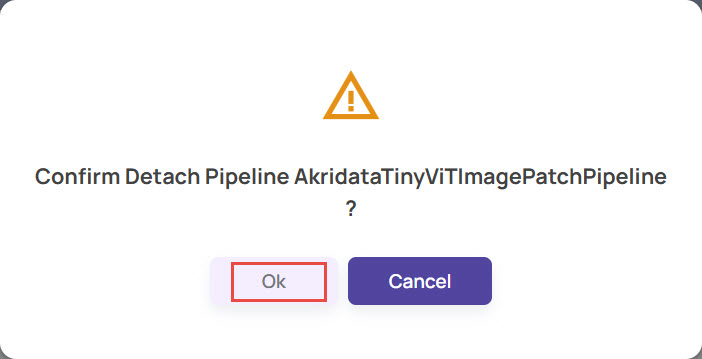
Detach the pipeline.
Edit the policy attached to the pipeline.
Detach Pipeline
Select Pipeline > Detach Pipeline.
.jpg)
Select the pipeline to detach from the drop-down list of attached pipelines.

Click the Detach button.
Ingested data stays after the 'Detach' operation
Any data ingested by the detached pipeline will remain in the system and be accessible for catalog browsing and job creation. The detached pipeline will not be executed on new data. If the same pipeline is reattached, all data that entered the dataset while the pipeline was detached will be processed through the reattached pipeline.