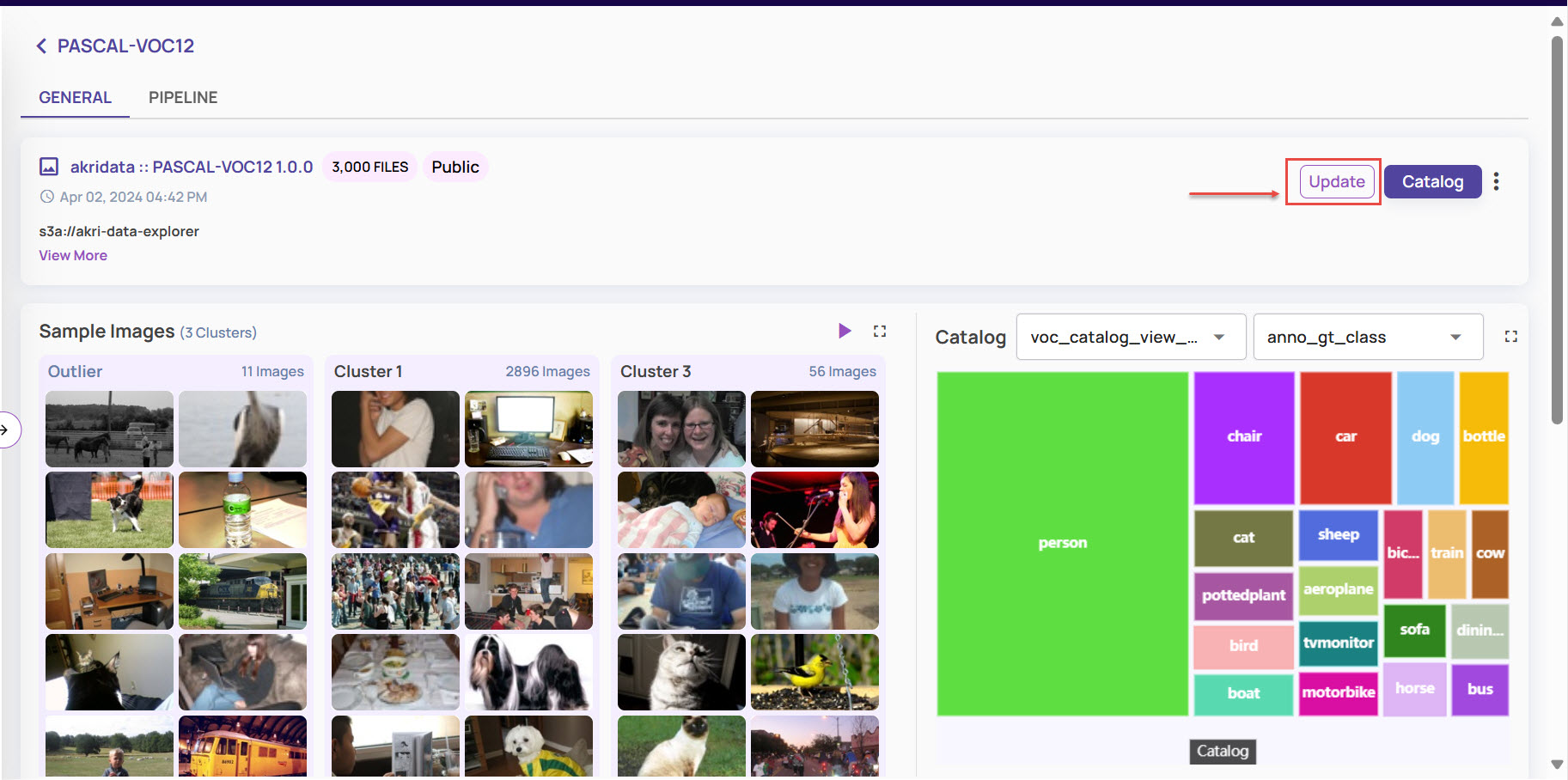
A dataset is an entity that holds a subset of data in a container along with all associated catalog tables and catalog views (virtual tables). The dataset page is available under Data > Dataset on the left navigation panel.
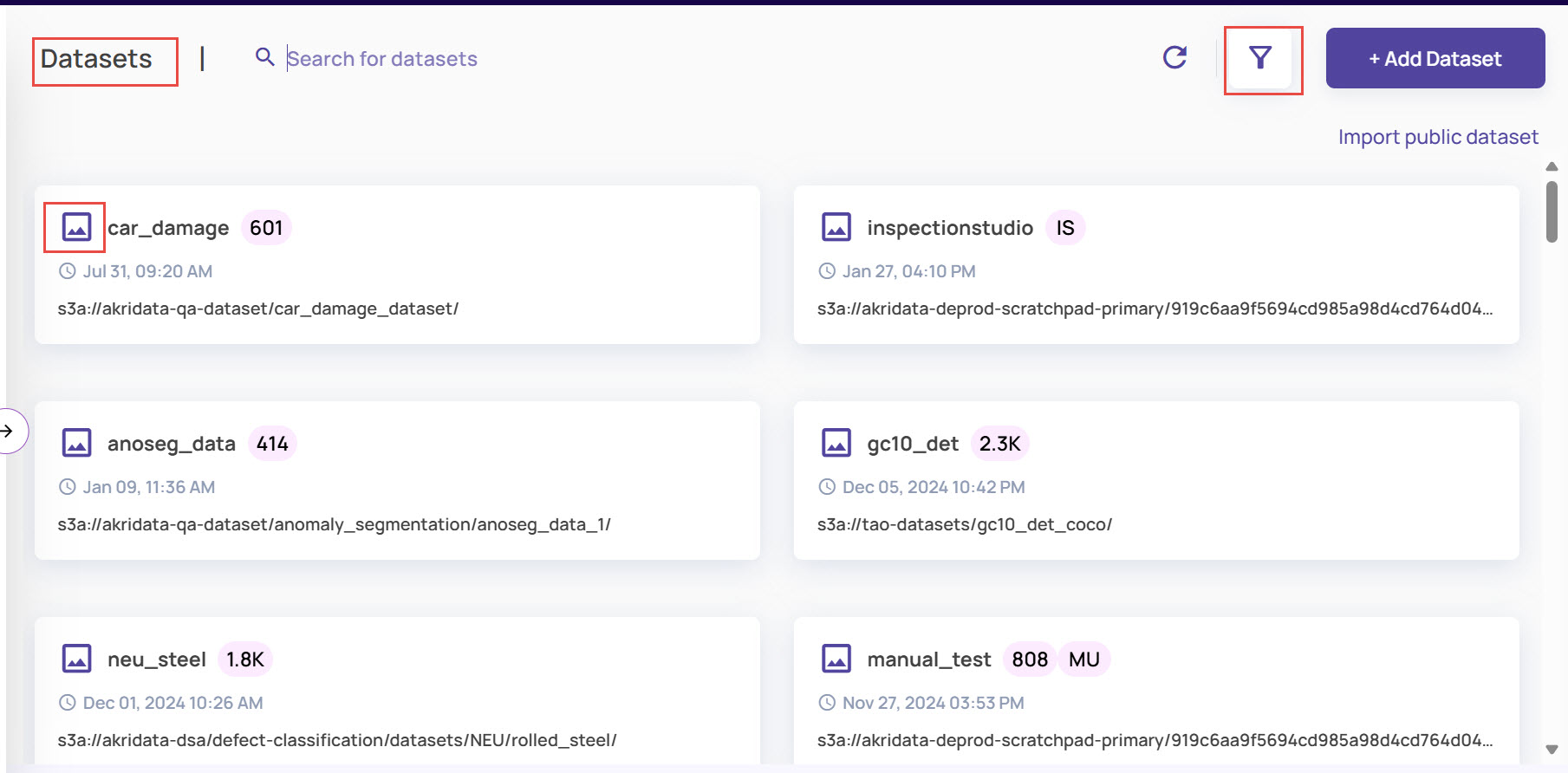
The Dataset page has the following information and controls:
Search box: To search for a dataset based on its name.
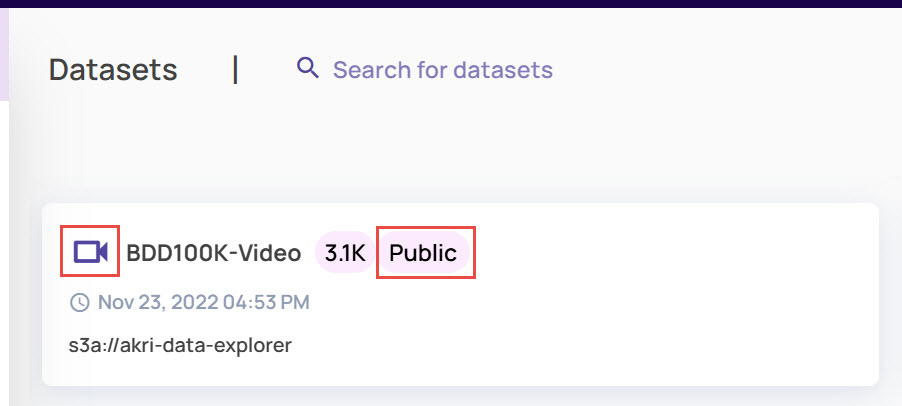
Dataset Type: Image or Video.
Public dataset: When a public dataset is imported as described in Import public dataset, a 'Public' badge is shown on the dataset card.
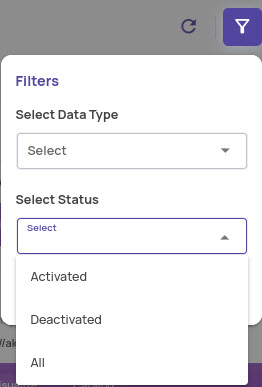
Filtering: Filter the page based on data type, status, and Dataset Type.
Data Type: You can filter by video or image data type.
Status: The status could be
Activated: A dataset on which new data can be registered and existing data can be accessed and visualized.
Deactivated: A dataset on which no new data can be registered. Existing data can be accessed and visualized.
Dataset Type: Filter datasets based on the following dataset types: Default, Datagen, Manual Upload, and Inspection Studio(Vision Command).
For example, when you search for Dataset Type as Manual Upload, all datasets of the matching type appear. You can identify such datasets with the label MU, as shown.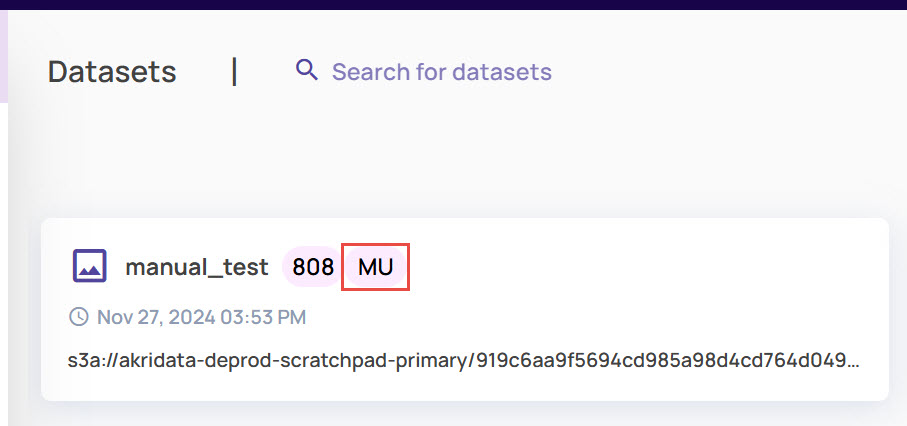
Similarly, projects of the Datagen type are labelled with DG, and projects of the Inspection Studio type are labelled with IS.
Catalog: Click the Dataset card, and on the dataset page, click the Catalog button.
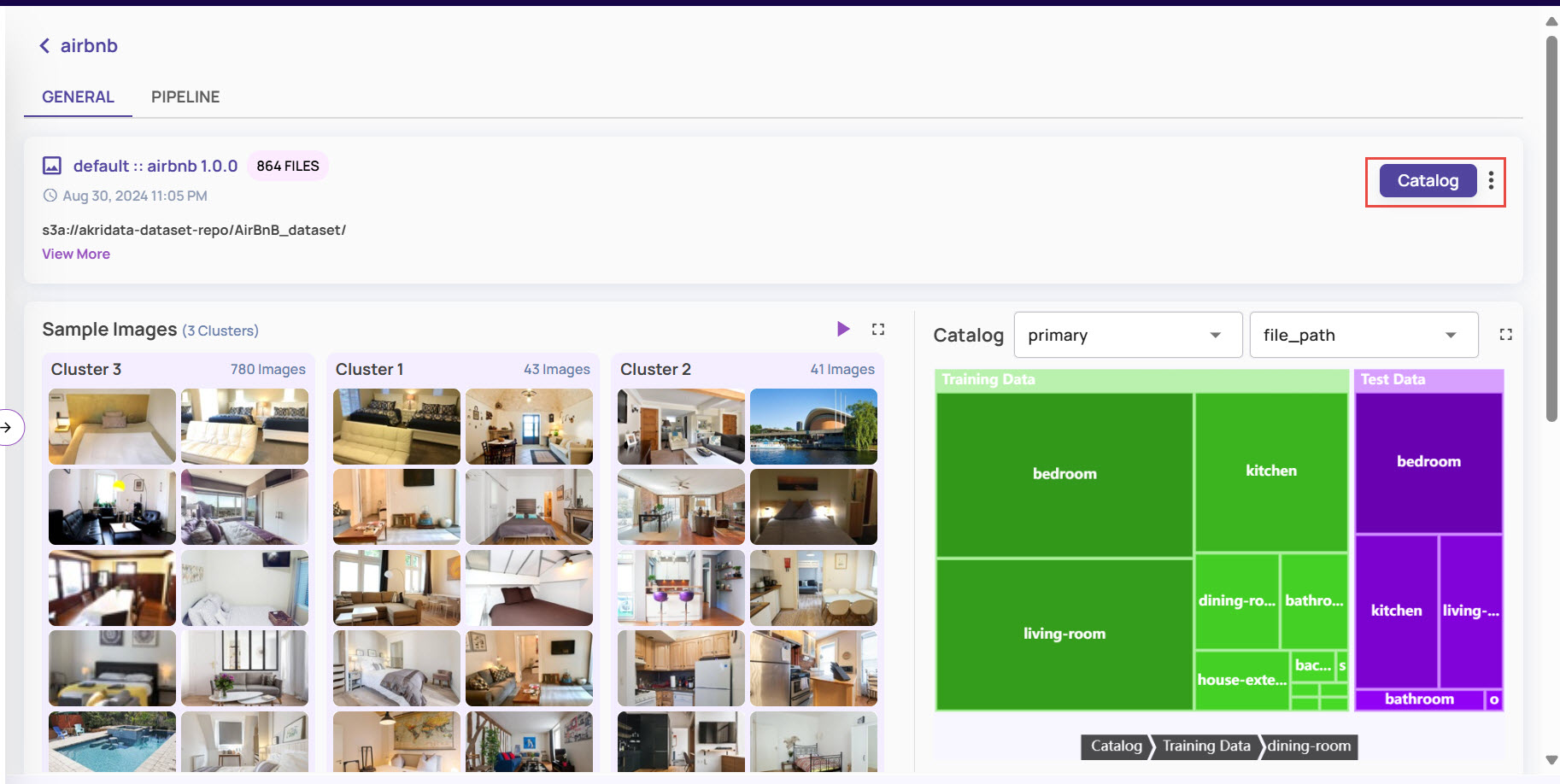
This opens the catalog page for the dataset, where all catalog-related operations like querying the catalog, importing external catalog, creating views, etc. can be performed.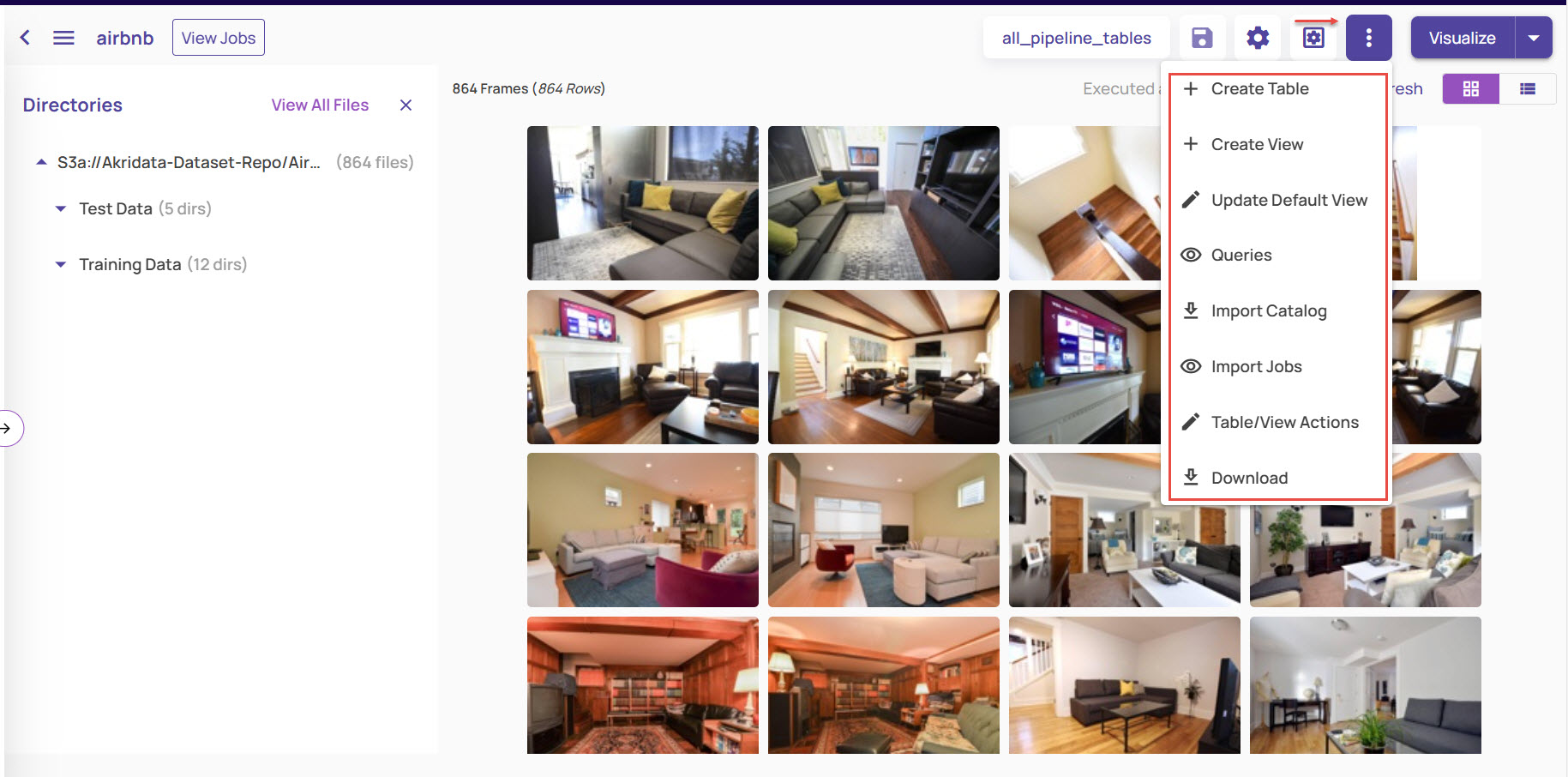
Update: If an update is available for a public dataset, an Update button appears to the left of the catalog button.